Python多线程基础
原理
并行与并发:
并行是真正的多任务一起执行,一个任务占用一个 CPU 核、CPU 的核心数大于等于任务数。
并发;是假的多任务 ,采用时间片轮转(一个时间片里面每个进程轮流运行一段时间。)和优先级调度(音视频等优先级较高)
CPU 的核心数小于任务数
线程:
线程(英语:thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
线程函数不能有返回值:
有以下几段文字参考:(虽然看完还是有点迷糊,但是比不看好了一些)
线程的执行本身是一个异步过程,当线程结束时,程序已经不是调用处的状态了。
一般情况需要用线程的话都是异步的,如果是需要等待返回值做处理的情况大部分都是同步的不需要用到多线程(除非是响应式,即线程执行完了,然后促发某个方法来处理某个结果),这种情况的话最好是单独设置一个静态变量来记录这个值,不是用返回值这种概念来做的。
这是目前最主流的获取线程数据的方法。使用 Queue 库创建队列实例,用来储存和传递线程间的数据。Python 的队列是线程安全的,也就是说多个线程同时访问一个队列也不会有冲突。Python 队列有三种 FIFO 先进先出,FILO 先进后出(类似栈),优先级队列(由单独的优先级参数决定顺序)。使用队列可以实现简单 生产者 – 消费者 模型
threading 模块
Python 的 threading 模块是比较底层的模块,threading 模块中有一个类叫做 Thread。
我们使用 Thread 类创建一个类对象,将来我们就用这个对象来启动一个线程。当我们调用该对象的 start 方法时,该方法会调用其内部的 run 方法,来创建一个线程
两种使用方法
函数
1 | def func(): # 这是一个函数 |
Thread 类创建一个对象(注:该类对象要传入一个 target 参数,写 函数引用,即:函数名。,然后 t1 调用它的 start 方法,来执行创建一个线程执行之前的 target 传入的函数 func。当创建 Thread 时执行的函数(target 传入的函数引用)运行结束,那么意味着这个子线程结束了。
主线程结束,程序才会结束。如果主线程不小心先结束了,那子线程也随之结束(即:主线程结束了,子线程会随之结束)。一个子线程在运行时会有一些自己的东西,主线程最后结束,便负责帮他们回收处理。
注:target 参数:只写函数名是函数引用,函数名() 是执行函数。target 参数只能够传函数名,不能传类。
当调用 Thread 的时候,不会创建线程。当调用 Thread 创建出来的实例对象的 start 方法时,才会创建线程并使线程等待系统调用。
当 Thread 类对象调用其 start 方法时,主线程会开启一个子线程,该子线程会等待系统调用,然后去执行之前类对象传入的函数引用对应的函数。至于什么时候调用是随机的,取决于系统的内核。
主线程执行完该执行的代码后,没有其他代码要执行时,会等待子线程结束之后再结束。
注:多线程中每个线程的执行顺序是不确定的。我们无法控制线程被调用的顺序,但可以通过别的方式(比如:time.sleep())来影响线程调度的方式。
类
如果要使用类时,需要:
1 | import threading |
定义一个类这个类继承自 Thread 类,这个类写一个 run 方法(有额外的方法随意,但是必须有 run 方法),start 方法会自动调用 run 方法。run 方法执行完了,这个线程就结束了。
适合于一个线程中做的事情比较复杂,而且我分成了多个函数去做。
你可以在 run 方法中调用 self.login()、self.register() 等方法来使用类中的 login 和 register 方法。
常用函数
treading 模块中常用函数有以下几个:
首先,我们看一下:
Note: While they are not listed below, the
camelCasenames used for some methods and functions in this module in the Python 2.x series are still supported by this module.
官方写到 Python 2.x 中驼峰式写法的函数仍被支持,即:Python 2.x 中函数为 currentThread 这样,Python 3.x 又来了一种,为 current_thread 这样。既然现在都 Python 3.7 了,我们还是用下划线的新版吧。(说着一点,还有一个意思,就是看到 currentThread 这样写的函数代码啥的要认识。)
current_thread
threading.current_thread() 返回调用当前代码的 Thread 对象。如果调用者控制的线程不是通过 threading 模块创建的,则返回一个只有有限功能的虚假线程对象。
main_thread
threading.main_thread()
返回主线程对象,在正常条件下,主线程是 Python 解释器创建开启的线程。
active_count
threading.active_count() 返回当前活着的Thread对象的个数。返回的数目等于enumerate()返回的列表的长度(所以就不用麻烦的使用 len(threading.enumerate()) 了)
enumerate
threading.enumerate()
返回当前活着的 Thread 对象的列表。该列表包括守护线程、由 current_thread()创建的虚假线程对象和主线程。它不包括终止的线程和还没有开始的线程。
threading 模块中有一个 enumerate(),它的返回值是一个列表,这个列表中拥有当前程序运行起来之后它创建的所有线程(包括其主线程。)
enumerate()
1 | for temp in names: |
通过 for 与 enumerate() 返回一个键值对,我们可以直接在写 for 时进行拆包。
线程的执行是没有先后顺序的,不确定的,这取决于内核的调度。
1 | import threading |
这里通过让主线程 sleep 一秒钟来达到使 t1.start 开启的线程先执行完,然后 t2.start 开启的线程再执行完,最后再执行 print 线程数目的目的。我们可以通过调整增减 time.sleep() 在 t1.start() 、t2.start() 以及他们执行的函数中的位置来调整打印线程。
通过以下测试我们也可以知道,线程创建是在 t1.start() 的时候。
1 | import threading |
我们可以使用 len 函数 通过判断 threading.enumerate() 的长度个数来判断是否子线程是否结束。
常用方法
Thread 类中常用方法:
Thread()
Thread(group=None, target=None, name=None, args=(), kwargs={}, **, daemon=None*)
常用到的参数: target :run() 方法调用的对象,即该线程做的事情,一般我们就写一个函数名
name : 线程的名字,默认情况下,会自动构造一个 “Thread-N” 格式(其中 N 是一个小的十进制数)的唯一的名字。
args : 一个参数元组,用来向 target 参数的对象传递参数
run():
用以表示线程活动的方法,当线程的 run() 方法结束时,该线程结束。
start():
启动线程活动,一个线程对象最多只能调用一次。它为对象的 run() 方法准备一个独立分离的控制线程。
join(timeout=None)
等待至线程中止。此方法会阻塞调用线程,直至线程的 join() 方法被调用中止(正常退出或者抛出未处理的异常或者是可选的超时发生。)
一般使用它来阻塞主线程,等待子线程结束,然后主线程去做后面的事情。
常见的场景是:将创建的多线程放到一个列表中,然后,当你想要保证主线程在所有子线程结束后做一些事情时,就要用到 join,我们可以使用 for 遍历多线程列表,从而阻塞主线程,直到每个子线程都结束之后,解堵塞。(join 是针对单个线程,我们循环就可以对每个线程依次 join)
多线程共享全局变量
在一个进程中的所有线程共享全局变量,有一个缺点:线程是对全局变量随意修改,可能造成多线程之间对全局变量的混乱(即线程非安全)
如果多个线程同时对同一个全局变量操作,会出现资源竞争问题,从而数据结果会不正确。
全局变量
如果想要在一个函数里面修改全局变量,不一定需要使用 global 关键字。
两种情况:
如果你要修改全局变量地址里面的值,可以直接修改。(当然,有的变量是不可修改的。)
如果你要修改全局变量的指向(即:使用包含 = 在内的一串赋值运算),那就不能直接修改,需要使用 global。
即:
如一个函数中,对全局变量进行修改的时候,是否需要使用 global,要看是否对函数的指向进行了修改。
如果修改了执行,即让全局变量指向了一个新的地方,那么必须使用 global ,如果,仅仅是修改了指向的空间中的数据,此时不必使用 global。
不修改,仅仅是获取全局变量,就不需要使用 global。
1 | num = 100 |
传参方式验证多线程共享全局变量
注意:args 要传一个元组,如果元祖只有一个参数,那么需要加个逗号,表明它是元祖。
即:
1 | g_num = [1.2] |
传参时这样写,写一个括号,括号内写传的参数然后用逗号隔开,
1 | type((1)) |
共享全局变量的问题
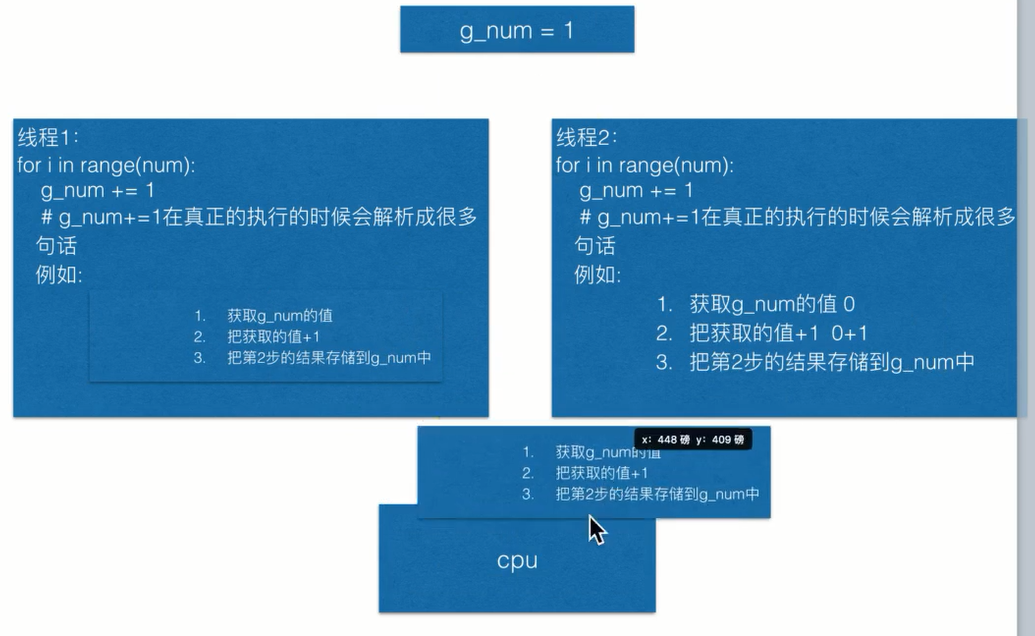
共享全局变量会造成资源竞争问题,执行次数越多出现错误的可能性越大
同步
同步就是协同步调,按照预定的先后次序进行运行。
对于共享全局变量造成的资源竞争的问题,我们可以通过线程同步来解决,即:加锁。
互斥锁(原子性)
当多个线程几乎同时修改某一个共享数据的时候(即同时进入临界区时),需要进行同步控制。
某个线程要更改共享数据时,先将其锁定。此时,资源的状态为 “锁定”,其他线程不能更改。直到该线程释放资源,将资源状态变成“非锁定”。其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
常见临界区:
- 修改某些临界变量等
- 多线程输出(向屏幕或者文件),容易造成粘连。
步骤
创建锁
mutex = threading.Lock()
上锁(锁定)
mutex = acquire()
上锁,如果之前没有被上锁,那么此时上锁成功。如果上锁之前已经被上锁了,那么此时会堵塞在这里,知道这个锁被解开。
释放锁资源
mutex.release()
上锁有一个原则:在实现功能的前提下,上锁的代码越少越好。
1 | import threading |
上面的加锁,有两种方式:
将锁加在 for 循环里面
1 | for i in range(num): |
这种情况下,只对 g_num += 1
进行加锁,那么多个线程的每次循环可能交叉运行,比如:线程一进行一次循环,然后线性二执行一次循环。此方法,不保证单个线程结果的唯一性与准确性,只保证多个线程的最后结果的唯一性与准确性。
将锁加在 for 循环外面
1 | mutex.acquire() |
这种情况下,多个线程的 for 循环不会交叉。只有一个线程的全部的 for 循环执行完毕后,另一个线程才可以获得锁资源。此方法,保证了本线程结果的唯一性与准确性。
死锁问题
死锁问题解决多个锁相互冲突的情况。比如:线程一对 mutexA 上锁,线程二对 mutexB 上锁,线程一、二在其上的锁未释放的情况下,又申请对方的锁,这样就会产生相互等待的死锁问题。
避免死锁:
- 程序设计时要尽量避免
- 添加超时时间
参考资料: