威胁情报
威胁情报现状与未来发展
《威胁情报技术应用及发展分析蓝皮书》 ——聚焦攻防,情报驱动,全面升级安全运营
本文看 威胁情报概述、威胁情报的历史及现状,威胁情报规模 三个部分就行,后面没啥看的感觉。
-
按阶段讲述了威胁情报的发展以及当前的现状。
节选
正因为威胁情报的潜力无限,所以信息安全行业真的很需要很多精通数据挖掘技术和机器学习技术的懂安全的工程师加入到这个行业中来,相信威胁情报的未来一片光明。
但是话虽这么说,一定要注意威胁情报只能用来辅助决策,不能用来直接决策,所以现在一般说威胁情报可以用来预测攻击的基本上都是 xxx 。与其他的技术相结合可以使威胁情报的作用最大化,诸如互联网攻击溯源、用户实体行为分析(UEBA)、事件调查与取证等技术结合威胁情报往往会产生意想不到的结果。
-
本文讲解的当前局势和未来发展都挺好的
A next-generation firewall (NGFW) is a part of the third generation of firewall technology, combining a traditional firewall with other network device filtering functionalities --wikipedia
下一代防火墙是第三代防火墙技术的一部分。它将传统的防火墙技术与其他具备过滤功能的网络设施结合起来。
我查着从 RSA 2014 就有 threat intelligence 这个概念了,然后 RSA 2015、2016、2017 逐渐火爆、成熟(2013 和 2018 没查 emm),2019 威胁情报依旧是 RSA 讨论的一个热点。
RSA 2019 想看哪一年,就把链接末尾的数字改一下就行了。
威胁情报的分类
根据生成的情报的优先级分类:
根据情报的信息来源分类:
威胁情报流程
威胁流程主要选自 安全小课堂第 128 期【甲方威胁情报生存指南】
简单来说就是:源数据 –> 自动化分析 –> 威胁情报
附上一张来自安全牛的图
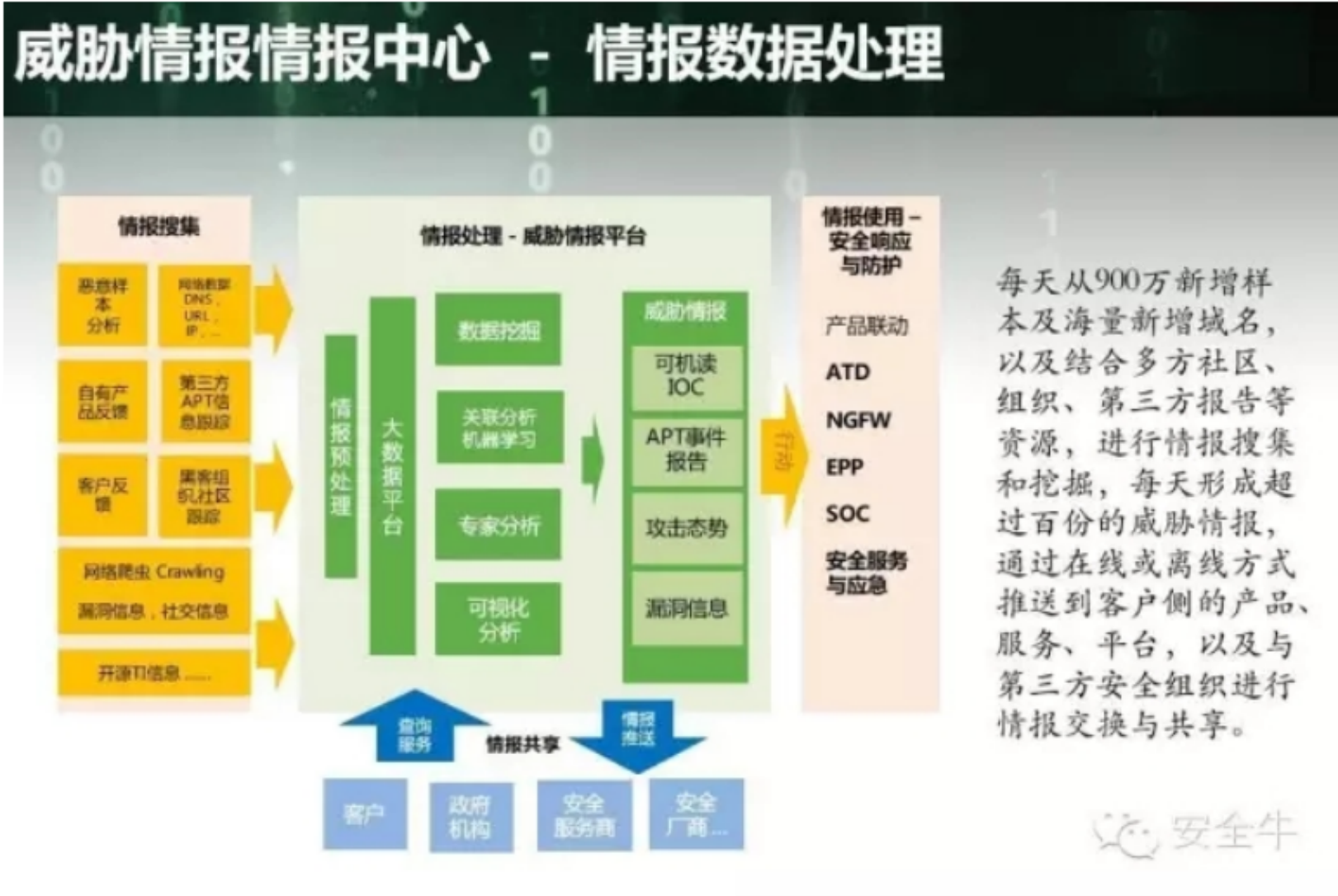
稍微再详细点:
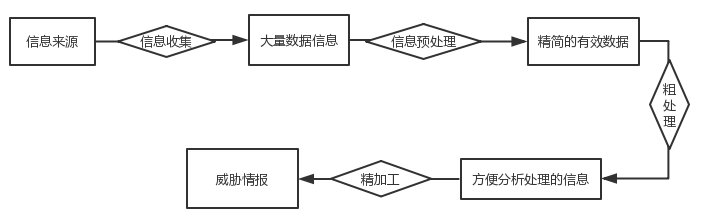
信息收集
就是按照情报来源的分类去收集,而收集的方法:对于资产情报直接去收集就好。
对于其他的情报,主要依赖网络爬虫和公开的 API 进行收集
通过爬虫收集分为两种:
第一种是公开信息收集
即可以通过类似于 selenium+scrapy 这种组合对特定页面的数据进行爬取落库操作
Google 开放服务里面提供一种服务叫做 Google CSE(Custom SearchEngine),这个东西可以利用 Google 的爬虫对特定的目标完成定制化的查找和排序,并且可以通过自带的 API 将搜索结果保存成 JSON 格式,以便和其他的平台进行衔接。用户只需要对 CSE 里面的规则进行编写即可完成这一部分的收集;
第二种是未公开信息收集
除了互联网之外,一些业务相关的安全信息更多的可能会出现在暗网,黑/灰产社群社区论坛等。
暗网的话可以使用 OnionProxy+OnionScan 进行收集,此外有一些暗网搜索引擎也提供了 API,可以进行和搜集。
鉴于黑产交易的渠道多为 QQ 群和微信群以及 Telegram,对于这一部分需要去使用聊天机器人对特定的几个黑产群的聊天记录进行爬取,github 上有很多公开的机器人 code(注意法律法规问题)
第三种是基于 RSS、订阅的信息
这种的话由于格式很规范,解析后直接落库即可,不需要花费太多的精力,推荐使用 rssparser 这种库去解析 RSS 的订阅源,有时候会收集到一些有用的东西。
信息预处理
信息预处理主要通过自动化处理去除一些明显虚假或无用的信息,减少搜集收集的信息。
粗处理
粗处理实际上是对爬取回来的信息进行格式化,比如说统一格式化成 JSON 格式或者是 XML 这种可以自动化处理的数据结构。
粗处理有时也可以和信息预处理一起。
精细加工
精加工主要是对情报进行更深层次的文本分析,可以利用诸如 NLP 技术、词频和词性分析、上下文理解的方法对情报信息进行提取,提取出来的关键字应包含该情报所影响的作用点、作用范围、是否受到影响、影响程度、是否需要推动应急响应流程。这一部分数据是需要格式化成特定格式的,方便与系统的对接,这里推荐使用 python 的 NLPIR、NLTK、Scikit-learn、Gensim 这种 NLP 的库去处理,方便且高效。
情报的挖掘
这里主要涉及到神经网络、关联学习、安全专家分析、可视化分析
内部情报
我们挖掘情报不一定需要从外部的数据去入手,相反实际上内部的数据往往是挖掘威胁情报的“金矿”。我们在对威胁情报挖掘之前需要理清楚两件事情,这两件事情是:
什么是正常的业务流程
业务会遭受何种类型的威胁
接下来我们需要针对我们设计好的场景去进行日志和流量的梳理,日志分析的主要是业务系统日志和访问日志,流量则是进行通信的流量 DPI 数据。通过持续化运营一段时间后,场景覆盖率提升到一定程度了
外部情报
部署蜜罐系统
你可以在公网上部署蜜罐系统,去对蜜罐的日志进行挖掘,当然这里主要是涉及到一些样本层面上的东西,如果运气好的话,也能够挖掘出来一些有用的新样本或者是 c2,取决于你有多少蜜罐的日志和蜜罐节点的分布。
首先我们要知道威胁情报是有针对性的,差异化的。对不同类型的企业/系统来说,有的威胁情报,可能对企业 A 来说是为威胁情报,但是对企业 B 来说,却没什么。
假设我们的业务系统很多都是 web 系统,所以 accesslog 是一个比较有价值的入手点
威胁情报的利用
威胁情报的共享和应用
威胁情报的数据可以共享出来,和业内一起配合使用。在 360 的威胁情报中心上,不管是威胁判定数据,还是关联数据、样本类数据等基础数据都会有。
在客户端数据的平台上,要能够把威胁情报双向应用起来,不管是推动起来,还是在查询和溯源上结合起来。情报是从数据中来,最后还要回到数据中去。威胁情报又是最终能够回到客户那边才能发挥它的作用,不管是安全和威胁的发现上,还是在自动化的响应过程当中,我们都把它结合得更好。