Python collections
知识点回顾
- Python 中数据类型可以分为 数字型 和 非数字型
- 数字型
- 整型 (
int) - 浮点型(
float) - 布尔型(
bool)- 真
True非 0 数—— 非零即真 - 假
False0
- 真
- 复数型 (
complex)- 主要用于科学计算,例如:平面场问题、波动问题、电感电容等问题
- 整型 (
- 非数字型
- 字符串
- 列表
- 元组
- 字典
Python Collections
Four collection data types
| collection | ordered | changeable | indexable | duplicate |
|---|---|---|---|---|
| List | ordered | changeable | indexed | Allow |
| Tuple | ordered | unchangeable | indexed | Allow |
| Set | unordered | changeable | unindexed | Not Allow |
| Dictionary | unordered | changeable | indexed | Not Allow |
- List is a collection which is ordered and changeable. Allows duplicate members.
- Tuple is a collection which is ordered and unchangeable. Allows duplicate members.
- Set is a collection which is unordered and unindexed. No duplicate members.
- Dictionary is a collection which is unordered, changeable and indexed. No duplicate members.
When choosing a collection type, it is useful to understand the properties of that type. Choosing the right type for a particular data set could mean retention of meaning, and, it could mean an increase in efficiency or security.
- 在
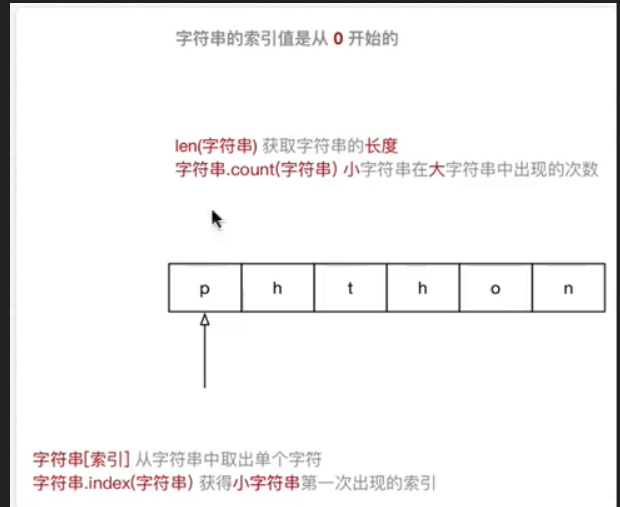
Python中,所有 非数字型变量 都支持以下特点:- 都是一个 序列
sequence,也可以理解为 容器 - 取值
[] - 遍历
for in - 计算长度、最大/最小值、比较、删除
- 链接
+和 重复* - 切片
- 都是一个 序列
列表
列表的定义
- 列表的 索引 从
0开始
注意:从列表中取值时,如果 超出索引范围,程序会报错
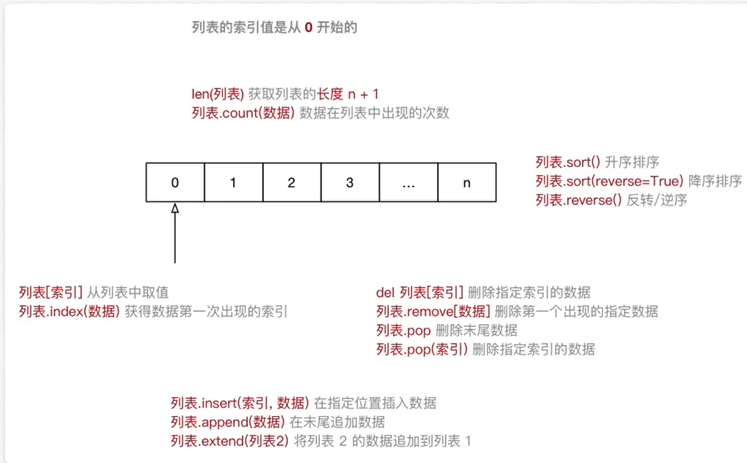
列表常用操作
- 在
ipython3中定义一个 列表,例如:name_list = [] - 输入
name_list.按下TAB键,ipython会提示 列表 能够使用的 方法 如下:
1 | In [1]: name_list. |
| 序号 | 分类 | 关键字 / 函数 / 方法 | 说明 |
|---|---|---|---|
| 1 | 增加 | 列表.insert(索引, 数据) | 在指定位置插入数据 |
| 列表.append(数据 | 在末尾追加数据 | ||
| 列表.extend(列表 2) | 将列表 2 的数据追加到列表 | ||
| 2 | 修改 | 列表[索引] = 数据 | 修改指定索引的数据 |
| 3 | 删除 | del 列表[索引](科普) | 删除指定索引的数据 |
| 列表.remove[数据] | 删除第一个出现的指定数据 | ||
| 列表.pop | 删除末尾数据 | ||
| 列表.pop(索引) | 删除指定索引数据 | ||
| 列表.clear | 清空列表 | ||
| 4 | 统计 | len(列表) | 列表长度 |
| 列表.count(数据) | 数据在列表中出现的次数 | ||
| 5 | 排序 | 列表.sort() | 升序排序 |
| 列表.sort(reverse=True) | 降序排序 | ||
| 列表.reverse() | 逆序、反转 |
sort()
- Definition and Usage
The sort() method sorts the list ascending by default.
This function can be used to sort list of integers, floating point
number, string and others.
You can also make a function to decide the sorting criteria(s).
- Syntax
list.sort(reverse=True|False, key=myFunc)
- Parameter Values
| Parameter | Description |
|---|---|
| reverse | Optional. reverse=True will sort the list descending. Default is reverse=False |
| key | Optional. A function to specify the sorting criteria(s) |
1 | In [32]: words |
append & extend
append 将其参数作为一个元素,追加到列表尾部, 列表的长度会+1 append adds its argument as a single element to the end of a list. The length of the list itself will increase by one.
extend 对其参数进行迭代,将其参数的每一个元素加到列表中扩展列表,列表的长度会增加可迭代参数中元素的个数那么多. extend iterates over its argument adding each element to the list, extending the list. The length of the list will increase by however many elements were in the iterable argument.
1 | In [37]: t_list = [1,2] |
del 关键字(科普)
- 使用
del关键字(delete) 同样可以删除列表中元素 del关键字本质上是用来 将一个变量从内存中删除的- 如果使用
del关键字将变量从内存中删除,后续的代码就不能再使用这个变量了
1 | del name_list[1] |
在日常开发中,要从列表删除数据,建议 使用列表提供的方法
关键字、函数和方法(科普)
- 关键字 是 Python 内置的、具有特殊意义的标识符
1 | In [1]: import keyword |
关键字后面不需要使用括号
- 函数 封装了独立功能,可以直接调用
1 | 函数名(参数) |
函数需要死记硬背
- 方法 和函数类似,同样是封装了独立的功能
- 方法 需要通过 对象 来调用,表示针对这个 对象 要做的操作
1 | 对象.方法名(参数) |
在变量后面输入
.,然后选择针对这个变量要执行的操作,记忆起来比函数要简单很多
循环遍历
- 遍历 就是 从头到尾
依次 从 列表 中获取数据
- 在 循环体内部 针对 每一个元素,执行相同的操作
- 在
Python中为了提高列表的遍历效率,专门提供的 迭代 iteration 遍历 - 使用
for就能够实现迭代遍历
1 | # for 循环内部使用的变量 in 列表 |
应用场景
- 尽管
Python的 列表 中可以 存储不同类型的数据 - 但是在开发中,更多的应用场景是
- 列表存储相同类型的数据
- 通过 迭代遍历,在循环体内部,针对列表中的每一项元素,执行相同的操作
列表常用方法
列表中的数据可变,类型可不一致
索引:
- 第一个元素索引为 0,倒数第一个元素索引为-1
- Range of Indexes 根据索引指定取 list 中的哪一段:list[2:5], 前闭后开,包含 list[2],不包含 list[5]。此外,:前或后的元素不 i 写,表示到头或尾。
1 | ports=[21,22,3306] |
append()方法
1 | ports.append('ssh') |
len(list) 长度
删除元素:
pop() 基于索引删除
The pop() method removes the specified index, (or the
last item if index is not specified):
1 | >>> ports.append(8080) |
remove 基于值删除
1 | >>> ports.remove('ssh') |
index()
The index() method finds the first
occurrence of the specified value.
确定值的索引,然后使用索引来修改值。如果不存在该值,会抛出异常
1 | ports.index(3306) |
find() 与 index() 类似,唯一区别是找不到值,会返回-1,而不会抛出异常。
rindex() The rindex() method finds the last occurrence
of the specified value.
1 | ip[0:ip.rindex('.')] |
list(str) 将字符串逐个字符拆分成列表
1 | list('hello') |
练习:
去除 IP 的 D 段:
1 | 方法一: |
元组:
元组不可变,只有:count 和 index 方法。
如果元组中只有一个元素,那么在元素后面必须加上逗号,否则就成了单个数字了。
1 | x=(1) |
字典:
列表中存放大量数据时,查找性能会下降。字典适合存储大量数据。
字典的优点是具有极快的查找速度,字典使用{}定义。字典使用 key:value 形式存储。each pair is called one item. 字典中的每个 key 与其 value 都是以冒号分隔,同时用都好分割每一项。
字典中没有索引,字典中的键是唯一的,值随便,可重复。字典中的值也可以改。
keys() 查看所有键
1 | service |
values() 方法查看所有值
1 | service.keys() |
字典的遍历:
遍历键:
1 | for i in service: |
遍历值:
1 | for i in service: |
同时遍历键和值:
1 | for i in service: |
元组
元组的定义
Tuple(元组)与列表类似,不同之处在于元组的 元素不能修改- 元组 表示多个元素组成的序列
- 元组 在
Python开发中,有特定的应用场景
- 用于存储 一串 信息,数据 之间使用
,分隔 - 元组用
()定义 - 元组的 索引 从
0开始- 索引 就是数据在 元组 中的位置编号
1 | info_tuple = ("zhangsan", 18, 1.75) |
创建空元组
注意:在开发中几乎不定义空元组,因为元组是不可变的。
1 | info_tuple = () |
元组中 只包含一个元素 时,需要在元素后面添加逗号, 否则就只是()中单个元素的那种类型
1 | info_tuple = (50, ) |
元组常用操作
- 取值与取索引
1 | In [22]: info |
In [27]: info.count(3)
Out[27]: 2
1 |
|
- 在
Python中,可以使用for循环遍历所有非数字型类型的变量:列表、元组、字典 以及 字符串- 提示:在实际开发中,除非 能够确认元组中的数据类型,否则针对元组的循环遍历需求并不是很多
应用场景
- 尽管可以使用
for in遍历 元组 - 但是在开发中,更多的应用场景是:
- 元组一般存储不同类型的数据
- 函数的 参数 和 返回值,一个函数可以接收
任意多个参数,或者 一次返回多个数据
- 有关 函数的参数 和 返回值,在后续 函数高级 给大家介绍
- 格式字符串,格式化字符串 % 后面的
()本质上就是一个元组 - 让列表不可以被修改,即:将列表转换为元组,从而达到保护数据安全的目的。
1 | info = ("zhangsan", 18) |
格式化字符串中的元组
1 | infor_tuple=("小明", 21, 1.78) |
元组和列表之间的转换
- 使用
list函数可以把元组转换成列表
1 | list(元组) |
- 使用
tuple函数可以把列表转换成元组
1 | tuple(列表) |
集合
Basically, sets are used for membership testing and eliminating duplicate entries。
一般有重复的数据,不要求去重的时候,不使用集合,可以使用列表遍历进行操作。
注意去重时,长度变化了,看你需要之前的长度,还是需要 len 重新计算一下长度。
可以使用大括号
{ }或者set()函数创建集合,注意:创建一个空集合必须用set()而不是{ },因为{ }是用来创建一个空字典。创建格式:
1
2
3parame = {value01,value02,...}
或者
set(value)集合只能容纳 immutable data type,不能容纳诸如:列表、集合、字典等可变数据类型。
1
2
3
4myset = {1,2,[1,2],"w"}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
常用操作
set.add(x)x 只能为一个不可变元素set.remove(x)将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误。set.discard(x)移除集合中的元素,且如果元素不存在,不会发生错误。set.update(iterable)将可迭代对象的元素加入到调用者集合,并去重。
Parameters: This method accepts iterable (list, tuple, dictionary etc.) as parameters. Return Value: It does not return anything, it just updates the calling Set.
1
2
3
4
5
6
7
8In [20]: set1 = {1,2,3}
In [21]: set2 = {3,4}
In [22]: set2.update(set1)
In [23]: set2
Out[23]: {1, 2, 3, 4}
集合运算
union()或|1
2
3
4
5
6
7In [36]: set1, set2
Out[36]: ({1, 2, 3}, {2, 3, 4, 5})
In [37]: set1 | set2
Out[37]: {1, 2, 3, 4, 5}
In [38]: print(set1.union(set2))
{1, 2, 3, 4, 5}intersection()或&1
2
3
4
5In [39]: set1 & set2
Out[39]: {2, 3}
In [40]: set1.intersection(set2)
Out[40]: {2, 3}difference()或-1
2
3
4
5In [41]: set1 - set2
Out[41]: {1}
In [42]: set1.difference(set2)
Out[42]: {1}symmetric_difference()或^1
2
3
4
5In [43]: set1.symmetric_difference(set2)
Out[43]: {1, 4, 5}
In [44]: set1 ^ set2
Out[44]: {1, 4, 5}
公共方法
字符串、列表、元组、字典都可以使用的方法。
Python 内置函数
Python 包含了以下内置函数:
| 函数 | 描述 | 备注 |
|---|---|---|
| len(item) | 计算容器中元素个数 | |
| del(item) | 删除变量 | del 有两种方式: 关键字、函数 |
| max(item) | 返回容器中元素最大值 | 如果是字典,只针对 key 比较 |
| min(item) | 返回容器中元素最小值 | 如果是字典,只针对 key 比较 |
| cmp(item1, item2) | 比较两个值,-1 小于/0 相等/1 大于 | Python 3.x 取消了 cmp 函数 |
del 方法/关键字:
1 | In [1]: a = [1,2,3] |
max/min 方法关键字:
注意: max/min 是针对字典的 key 进行统计比较
1 | In [18]: t_dict = {"z":"hello", "a":"world"} |
比较
使用比较运算符进行字符串、列表、元组的比较。
- 字符串 根据 ASCII 码比较: "0" < "A" < "a"
- 列表、元组是逐个对应元素进行比较
- 没有字典比较的需求。字典之间不能比较,字典是无序的。
1 | In [24]: "12" > "23" |
切片
:---: | ------------------ | ------- | ------------------ | |
切片 | "0123456789"[::-2] | "97531" | 字符串、列表、元组 |
- 切片 使用 索引值 来限定范围,从一个大的 字符串 中 切出 小的 字符串
- 列表 和 元组 都是 有序 的集合,都能够 通过索引值 获取到对应的数据
- 字典 是一个 无序 的集合,是使用 键值对 保存数据,字典无序,没有索引的概念,也就不存在切片。
切片超出索引不报错
当我们直接以索引值来访问 collection 的元素时,如果超出范围会报错 但是可切片的对象(有索引的对象)在切片中的索引超出范围时,不会报错。这样就不用考虑边界问题了。
1 | In [13]: text = "hello" |
列表,元组和上面一样。
例题 text-wrap 知识点:
- range 的 step 参数
- 切片超出范围不报错
1 | def wrap(string, max_width): |
判断序列是否空
PEP8 里面推荐的判断非空的方法: if seq python 在求
sequence (string, list, tuple) 的 bool 值的时候会把空的给 evaluate 成
False。
For sequences, (strings, lists, tuples), use the fact that empty sequences are false.
1 | Yes: if not seq: |
PEP 0008 -- Style Guide for Python Code
运算符
| 运算符 | Python 表达式 | 结果 | 描述 | 支持的数据类型 |
|---|---|---|---|---|
| + | [1, 2] + [3, 4] | [1, 2, 3, 4] | 合并 | 字符串、列表、元组 |
| * | ["Hi!"] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 | 字符串、列表、元组 |
| in | 3 in (1, 2, 3) | True | 元素是否存在 | 字符串、列表、元组、字典 |
| not in | 4 not in (1, 2, 3) | True | 元素是否不存在 | 字符串、列表、元组、字典 |
| > >= == < <= | (1, 2, 3) < (2, 2, 3) | True | 元素比较 | 字符串、列表、元组 |
+ 与 extend 的区别:
+ 不改变原列表,生成一个新的列表,extend
直接扩展改变原列表, 不生成新列表。当然, append 方法也是修改原列表。
1 | In [48]: t_list |
注意
in / not in在对 字典 操作时,判断的是 字典的键in和not in被称为 成员运算符
1 | In [56]: "name" in {"name":"laowang"} |
成员运算符
成员运算符用于 测试 序列中是否包含指定的 成员
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False | 3 in (1, 2, 3) 返回 True |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False | 3 not in (1, 2, 3) 返回 False |
注意:在对 字典 操作时,判断的是 字典的键
完整的 for 循环语法
Notice: 《Effective Python》不建议使用该语法, 不要在 for 和 while 循环后面写 else 块
- 在
Python中完整的for 循环的语法如下:
1 | for 变量 in 集合: |
当集合遍历完成后, else 代码块就会被执行。 如果中途通过
break 退出循环,导致集合未遍历完成,那么 else
代码块就不会被执行。
可以看出,else 内的语句会在循环语句结束后立即执行。但是很奇怪,为什么叫 else 呢?
常用的 else 如 if/else,try/except/else 等都是前面的代码块不执行才执行 else 语句。所以不熟悉此语法的人可能会误认为:如果循环没有正常执行完,那就执行 else 块。但实际上正好相反,循环正常执行完会立即执行 else 代码块;在循环里用 break 跳出(即使是最后一个循环 break),会导致程序不执行 else。
因此,循环后面的 else 代码块没有必要且容易引起歧义,尽量不要使用。
应用场景
- 在 迭代遍历 嵌套的数据类型时,例如 一个列表包含了多个字典
- 需求:要判断 某一个字典中 是否存在 指定的 值
- 如果 存在,提示并且退出循环
- 如果 不存在,在 循环整体结束 后,希望 得到一个统一的提示
1 | students = [ |
补充
Python 中三元运算符的写法
1 | In [9]: a=3 |