Linux 下使用 Python OCR 识别
Preparation
Notice
manjaro kde 用户直接看下面的安装总结,一把梭哈。
screenshot tools
Spectacle 为 KDE 桌面自带的官方屏幕截图工具,功能强大,使用舒适,推荐使用哦。 本来想通过 flameshot 的命令行来实现截图并存储到指定位置的,然而它的命令行不能够截取部分区域,只能截取整个桌面或者屏幕。
我知道的其他可以使用截图工具的有: scot、gnome-screenshot
参考命令(截取指定矩形,并存储到指定位置):
scrot -s -o ~/Documents/temp.png、gnome-screenshot -a -f ~/Documents/temp.png
注:个人认为 spectacle 比 scrot 截图可视化做得好, 即:截取区域时,可以明显看见,而且截取完了,可以再改变或者与移动区域。
tesseract-ocr
Introduction
tesseract 是一款被广泛使用的开源 OCR 工具,在现在的免费 OCR
引擎中,其识别精度类较好的,也广泛被使用。tesseract 作为开源项目发布在
GitHub 上,其最新版本已经支持中文 OCR,并提供了命令行工具,此外,还有
Python 库 pytesseract。
Installation
各发行版 Linux 一般对应仓库都有包,我使用的是 Manjaro,得益于其强大的社区以及用户仓库,安装软件一句命令行搞定。
安装 Tesseract
sudo pacman -S tesseract安装语言文件
方法一:
sudo pacman -S tesseract-data-chi_sim tesseract-data-eng方法二: 直接在 Github tessdata 下载,然后将其移动到 tessdata 对应位置即可。 manjaro linux 的位置是
/usr/share/tessdata/, 其他 Debian based Linux 可能是/usr/share/tesseract-ocr/tessdata。
检查是否安装好
该命令显示出安装过的语言数据包(我多安装了两个)。
1 | tesseract --list-langs |
Baidu OCR
Introduction
我使用的是百度 OCR 的 SDK(为啥没直接 API,额,第一眼看到了 SDK,就用了 emm)。后面才发现 SDK 不太适合对含位置信息版的接口进行二次处理,扩展功能,等有空再搞吧。
Installation
pip install baidu-aip- 申请 API 接口 后面填到脚本对应位置。 申请教程参考:如何申请百度文字识别 apikey 和 Secret Key
其他 Python 第三方库
pytesseract 调用 tesseract:
pip install pytesseractpyperclip 处理剪切板中纯文本与 Python 的交互:
pip install pyperclip依赖xclip或者xsel, 安装命令:sudo pacman -S xclip
pillow 处理图片: pip install pillow
安装总结
安装
1
2sudo pacman -S xclip tesseract tesseract-data-chi_sim tesseract-data-eng
pip install baidu-aip pytesseract pyperclip去百度智能云创建文字识别应用,并获取该应用三个信息 详细步骤见 如何申请百度文字识别 apikey 和 Secret Key
APP_ID、API_KEY、SECRET_KEY
脚本编写
脚本思路
利用截图软件 spectacle 截取需要被文字识别的部分;
利用百度 OCR 或者文字识别 OCR 软件 tesseract 进行识别 参数控制有无网络,使得有网络用百度, 无网络用 tesseract
将结果输出至剪切板 参数控制是否需要段落整理(在你识别段落文字时,很重要,不处理的话,换行之类的格式较乱),通过正则进行段落整理。
学习历程
查阅学习 spectacle
spectacle --help查阅学习 tesseract 基本命令;
tesseract --help-extra查阅学习 百度 OCR SDK 文档,并学习 baidu-aip 模块基本使用 baidu OCR SDK Python 文档
学习 pytesseract、pyperclip、pillow 模块基本使用
学习 Python 调用 shell 命令
Python 代码
注意:
- 将临时路径 TEMP_IMG_PATH 自己设置一个。
- 在脚本中搜索 "Notice",找到百度 API
信息的位置,补充之前你创建的百度文字识别应用的信息:
APP_ID、API_KEY、SECRET_KEY
快捷键设置
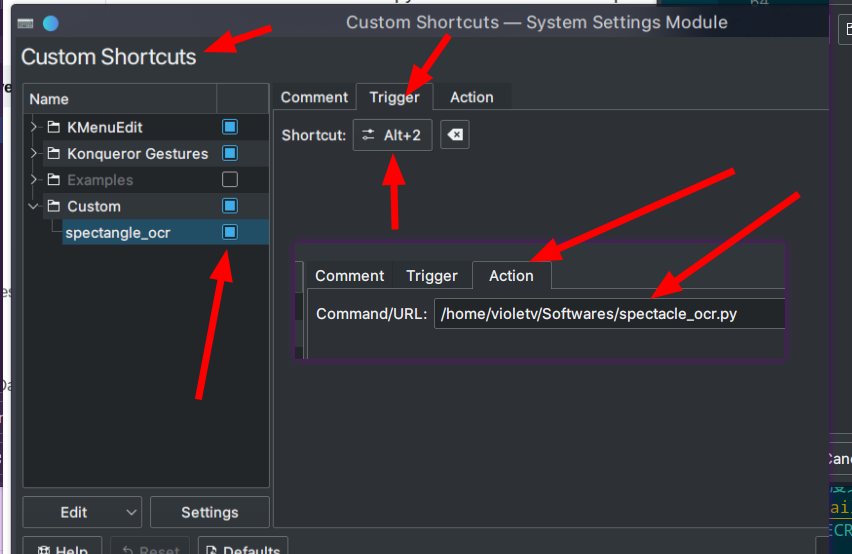
问题与改进
截图图片作为中间产物
本脚本使用了外部截图工具截图后放到指定位置,然后从该位置获取图片,这样存储读取速度就慢了些,而且产生了中间产物:一张截图。
我尝试解决这个问题,发现常用的方法有两种:
使用 pillow 模块的
ImageGrab.grabclipboard()获取剪切板的截图从下面链接可以看出,该方法只是用于 Windows 和 OS X。 ImageGrab Module (OS X and Windows only)
因此,我尝试搜索 ”ImageGrab Linux alternative“ 找到了 ImageGrab alternative in linux,也就是: pyscreenshot
然而, pyscreenshot 并没有 grabclipboard 方法,直接获取剪切板图片,而是可以直接截图,这就很高级了。通过搭配 python 的
pynput库来监听键盘实现快捷键截图,监听鼠标确定截图区域。这样,就直接避免了使用截图工具和产生中间图片的问题,Great!
使用 Qt 或者 GTK 图形界面框架来进行截图与获取截图后的图片至 Python 对象。
这当然选 Qt 了,一方面学过 Qt 的一些知识,一方面我用的 KDE 桌面是使用 Qt 开发。