Actor Critic Method
Actor Critic Method
Introduction
actor 是策略网络,用来控制 Agent 去运动,可以把它看作是运动员。critic 是价值网络,用来给动作打分,可以把它看作是裁判

下面我们学习 Value Network 和 Policy Network
Value Network and Policy Network

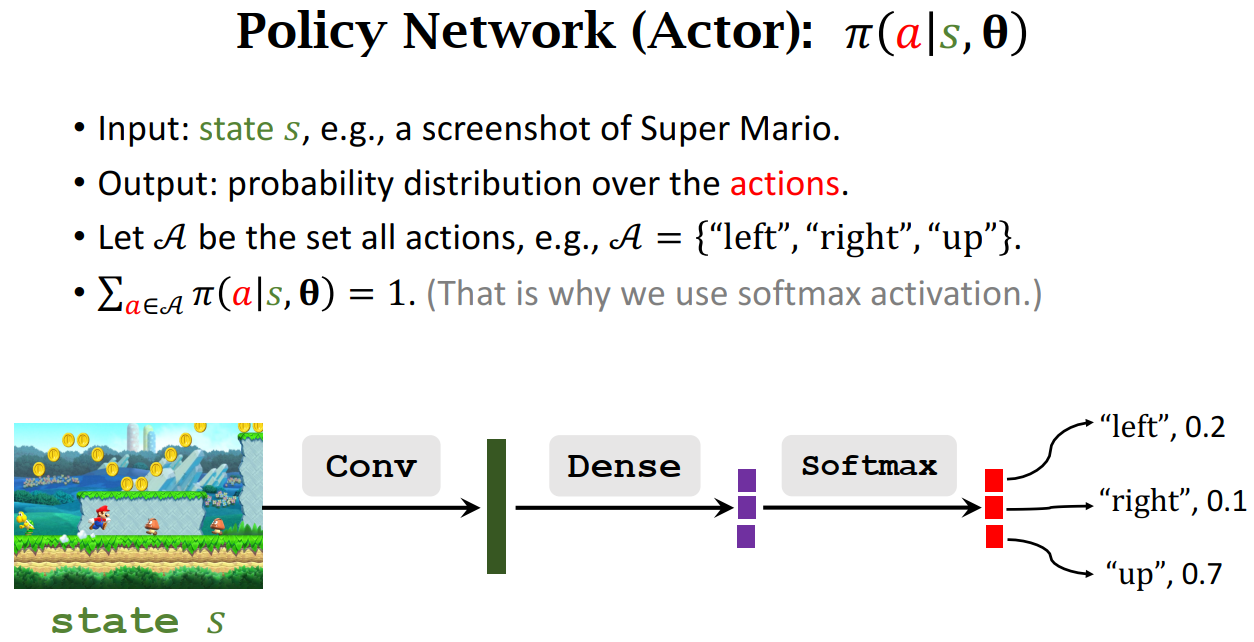
Policy Network (Actor): 𝜋(𝑎|𝑠,𝛉)
Value Network (Critic): 𝑞(𝑠,𝑎;𝐰)
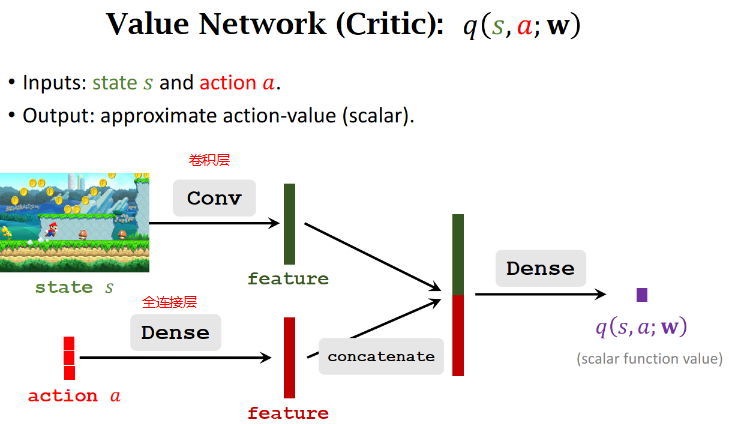
这个价值网络和策略网络可以共享卷积层的参数,也可以跟策略网络完全独立。
Train the networks


Update value network q using TD

Update policy network π using policy gradient

Actor-Critic Method
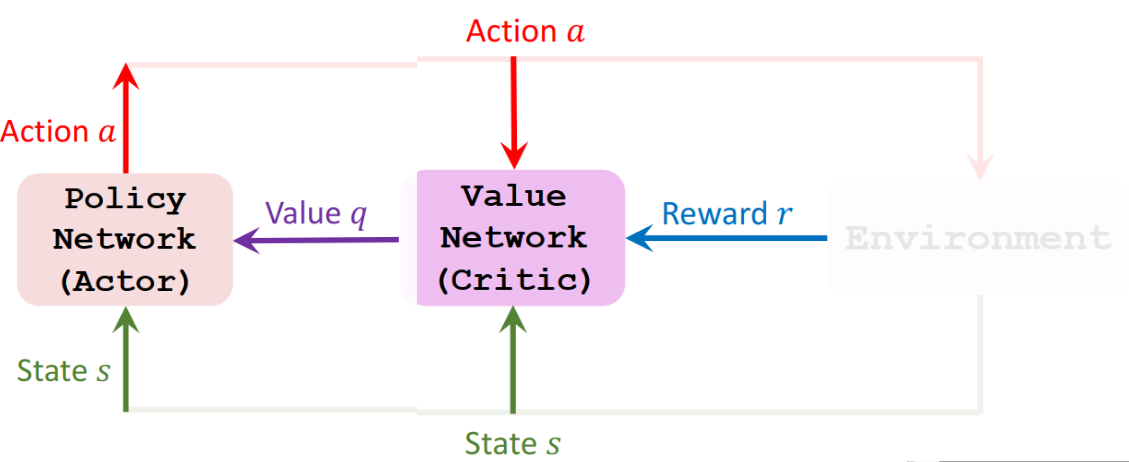
Actor
Policy Network(Actor) 观测到当前状态 S,然后做出动作 a, Actor 做出动作之后,Critic 会根据状态 S 和动作 a 来打一个分数记为 q,并将其告知 Actor,这样 Actor 就有办法改进自己的技术了。
Actor 要靠 Critic 反馈来改进自己的技术,也就是更新神经网络的参数,它通过 State s, Action a 和 Value q 来近似算出策略梯度,然后做梯度上升来更新自己的参数。
其实这只是在迎合 Critic 的喜好而已,因此如果想要 Actor 更好,那么 Critic 的水平也要好。
Critic
critic 靠 reward 来提高打分水平,裁判基于状态 S 和动作 a 来打分,计算出价值 q,可以比较相邻两次 \[q_{t}、q_{t+1 和 $r_{t}\],用 TD 算法来更新相邻两次打分,这样可以让裁判打分更精准。
Summary of Algorithm
每一轮迭代进行下面九个步骤,每一轮迭代中只做一个动作,观测一次奖励,更新一次神经网络的参数。

如果看论文和教科书,你会发现在其中第九步的 \(q_{t}\) 它们常常使用 \(\delta_{t}\),也就是 TD error. 这两种都是对的。使用 \(q_{t}\) 是标准算法,使用 \(\delta_{t}\) 是 policy gradient with baseline,两种都可以用数学推导出来。实际上,使用 policy gradient with baseline 效果更好,因此大家往往使用它。
原因:用或者不用 baseline, 并不影响期望(二者都是一样的),但是用得好的 baseline 可以降低方差,让算法收敛的更快。
Role of Actor and Critic
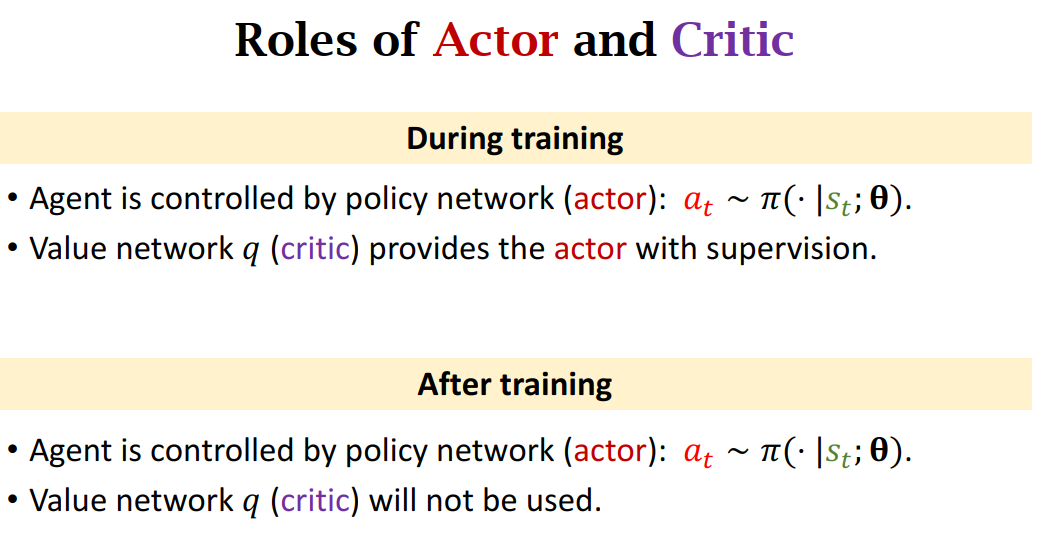
Training
