Value-based Method of RL
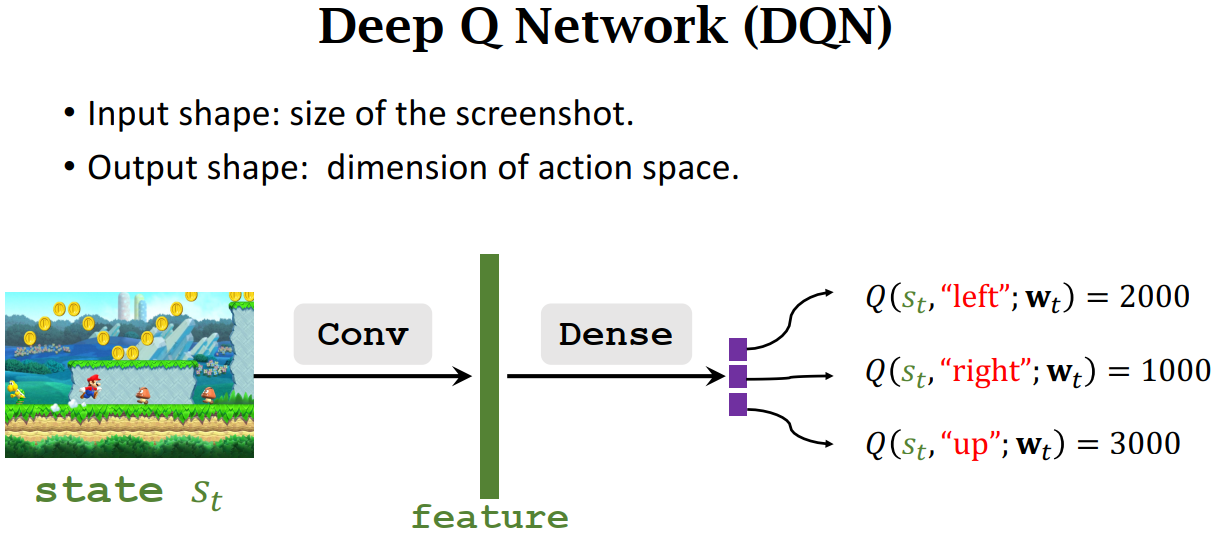
Deep Q-Network
Goal: Win the game (≈ maximize the total reward.)
Question: If we know \(𝑄^{\star}(𝑠|𝑎)\), what is the best action?
- Obviously, the best action is \(a_{t} = argmax_{a}Q^{\star}(s_{t},a)\)
Challenge: We do not know \(𝑄^{\star}(𝑠|𝑎)\).
- Solution: Deep Q Network (DQN)
- Use neural network \(𝑄(𝑠,𝑎;𝐰)\) to approximate \(𝑄^{\star}(𝑠|𝑎)\), DQN 输入当前状态 S,输出动作空间
Apply DQN to Play Game
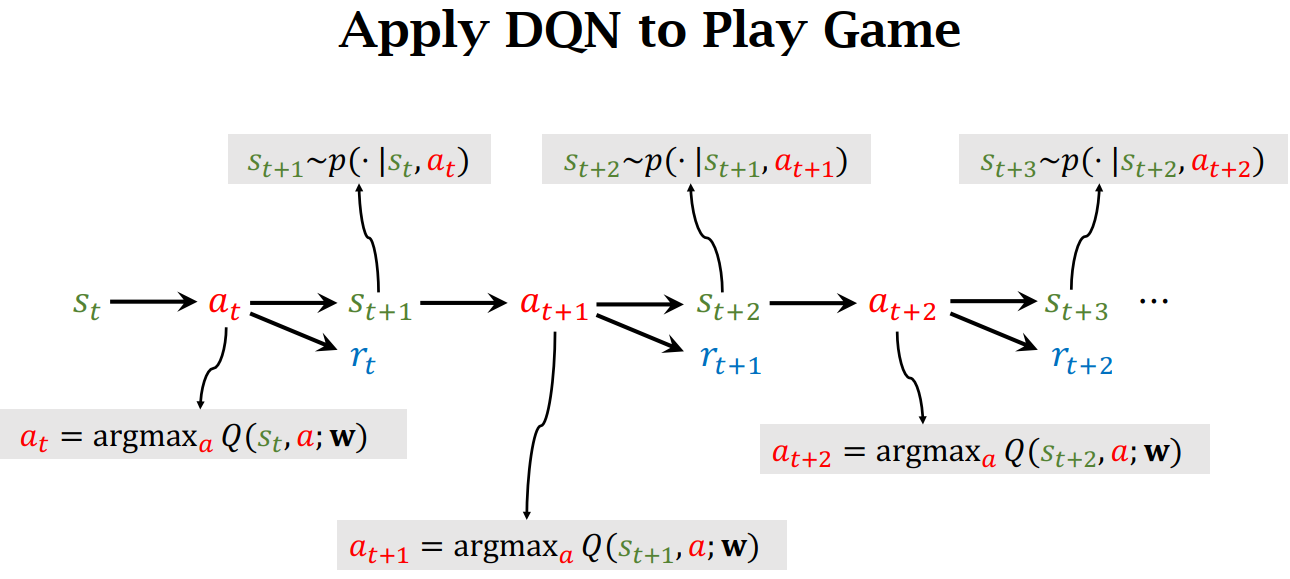
- 观察环境, 获取状态 \(s_{t}\), 也就是 Observation
- 向 DQN 输入状态 \(s_{t}\),获得使其最大化的动作 \(a_{t}\)
- 环境接受到 agent 的动作影响,通过状态转移函数 \(s_{t+1}~p(\cdot|s_{t},a_{t})\) 获取下一个状态 \(s_{t+1}\)
- 环境同时给出本轮的 reward
状态价值函数的估算
Monte-Carlo Policy Evaluation


时序差分方法 Temporal-difference (TD) -- 单步更新
- Can I update the model before finishing the trip?
- Can I get a better 𝐰 as soon as I arrived at DC?
That's TD learning!

TD error

Apply TD learning to DQN
想要使用 TD 算法,必须等式左边有一项,右边有两项,右边两项中有一项为真实观测到的。
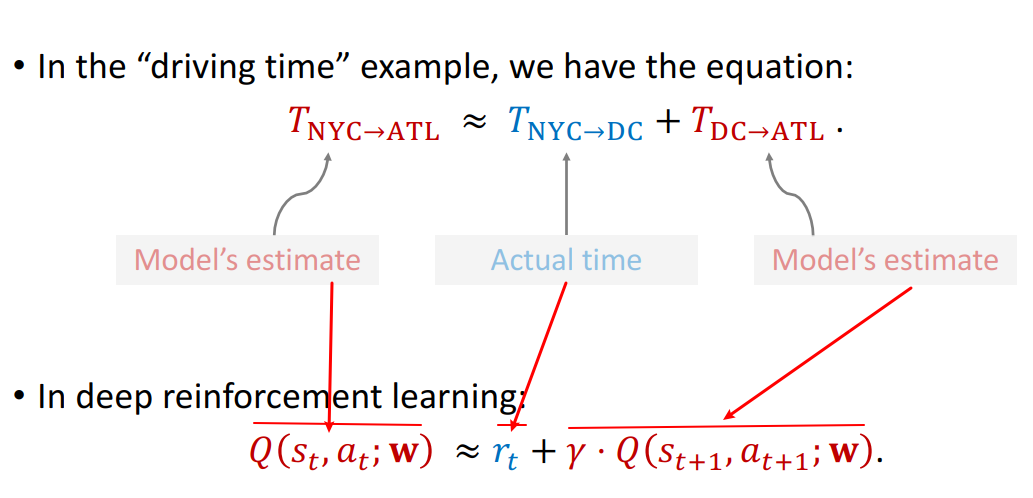
简要的推导证明:

Train DQN using TD learning
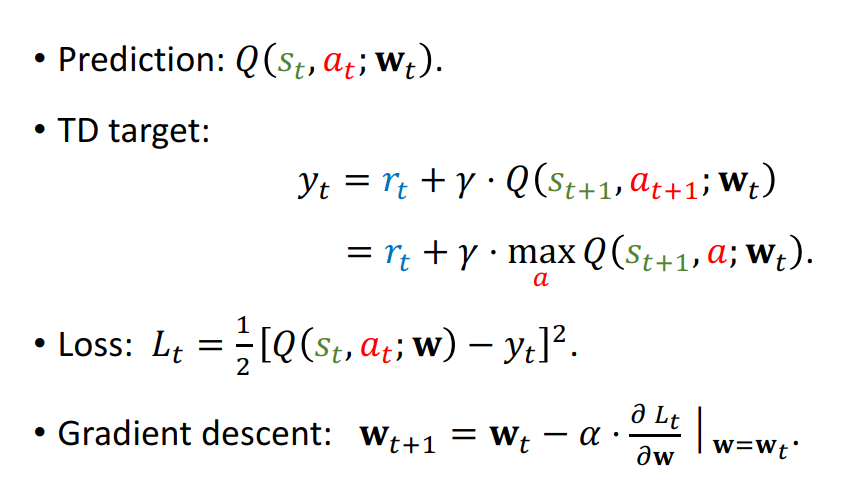
\(Q(s_{t+1},a_{t+1}, w_{t})\) 的值实际上等于把 a 当作变量求得的最大化 Q 值
One iteration of TD learning
