Python Regexp 原理与语法
- 1. Online RegExp Debug
- 2. 好的资料
- 3. Python Regular Expression Terminology
- 4. 基本使用
- 5. 原始字符串
- 6. 注意事项
- 7. Regular Expression Engine - Five Key Point
- 8. Regular Expression Proformance
- 9. 4.2. Issues and Fix
- 10. Module Versus Compiled Regex Method Invocation
- 11. Match Unicode Characters
- 12. 参考资料
本文并未覆盖 Python 正则的全部知识,网上优秀的教程很多,无需重复,这里只记录一些易忘点、难点以及好的索引链接
Online RegExp Debug
regex101 注意测试时,在右侧的语言栏选择 Pyhton debuggex JavaScript Regular Expression Visualizer.
好的资料
2018 Python Regular Expressions - Real World Projects
这两个资料我是依次都看完了的。第一个是 oreilly 的课程,深入潜出,是我第一次完整地学完一套英文教程,很是欣喜。 第一个教程(几乎)没有讲 lookahead 和 lookbehind 等 zero-width assertion 知识,因此,我找到第二个资料,把它看了一遍。
只看教程,不动手学不好,如果暂时找不到实际项目用处,可以先刷一刷题目,各大刷题网站均可,我当时刷的 hackerrank(为啥?因为我当时谷歌英文搜索正则练习题目的时候,它排在前面,哈哈)
Python Regular Expression Terminology
- Pattern - A text pattern of interest expressed in Regular Expression Language
- Text – String in which to look for a match with a given pattern
- Regex Engine - Regular Expression Engine that does the actual work
- Regex Module – Python module for interacting with Regex Engine.
Module: re
基本使用
re 模块简单使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16In [10]: import re
In [11]: test = """
...: hello 12 world
...: Goodbye 224 world
...: h yet anothet 'h'
...: """
In [15]: pattern = r"\d{1,}"
In [16]: match_obj = re.search(pattern, test)
In [17]: print(match_obj)
<re.Match object; span=(7, 9), match='12'>
In [18]: print(match_obj.group())
12
详细的 Python 正则函数与方法的使用等在另一篇博文写。
原始字符串
为什么 pattern 写的时候,需要使用原始字符串?
Python 中有关 rawString(raw 字符串)的理解 7.2. re — Regular expression operations
注意事项
Reserved characters
Reserved characters such as
{ } [ ] / \ + * . $ ^ | ?will not be reserverd in sets, which means there is no need to escape Reserved characters in sets. 例如,[(+*)]将匹配任何文字字符 '(' , '+' , '*' 或 ')' 。Reserved characters in group or Zero-width assertions still need to be escaped
|An alternator at this position effectively truncates the entire pattern, rendering any other tokens beyond this point useless引号并不影响
\b边界的匹配,就是说,即使一个单词挨着多个引号,正则引擎也会把匹配该单词。^、$将逐个输入作为一个字符串,只作用于该字符串的开头和结尾,如果你想要把每一行单独对待,匹配它们的开头,则需要使用mflag 当匹配开头/结尾时,如果想将每行的开头/结尾单独出来看,也可使用 multi-mode inline option对于取反,
^需要是[]中开头第一个字符, 否则它就变成了字面意思的^。
Conditional Expression
Learn about branching in regular expressions.
if ... then ... else: n -> group number name -> group name
(?(n)yes_expression | no_expression)
(?(name)yes_expression | no_expression)
如果 group n 或者 group name 的条件满足了,那么就执行 yes_expression, 否则执行 no_expression
这个就像 (A|B) 的升级版, (A|B) 是或者 A 或者 B,而它加一个
?(n),对前面的分组进行判断,就成为了((?(n))A|B)。
Example
if starting character is digit, text need to 3 digits else text neads to be 4 letters
Pattern 1: \b(\d)?(?(1)\d{2}|[a-z]{4})\b 如果 ?(1) group
1,即: 满足了,那么执行 匹配,否则执行[a-z]{4},然后两边都有 word
boundary.
Pattern 2:
\b(?P<test>\d)(?<test>\d{2}|[a-z]{4})\b
or simply: \b(\d{3}|[a-z]{4})\b 匹配 3 个数字或者 4
个字符。
Regular Expression Engine - Five Key Point
Regular Expression Engine Introduction
Python, Perl, .Net Regular Expression Engines 属于不确定有限状态自动机(Nondeterministic Finite Automation)的一类实现。
Pattern 驱动着正则引擎处理输入文本,并选择恰当的路径。
牢记之前的成功状态,以防遇到不完整匹配时,可以退回之前成功匹配的状态,尝试其他路径(这里和自己用 c 指针写字符串匹配类似) Regex 引擎本质上是通用的,并按照模式中的指示采取路径。它依赖于开发者定义有效的 pattern 来指导引擎。
Five key Points
One Character at a time
It compares and matches one character at aa time.
Left to Right
Pattern is traversed left to right. Text also is traversed left to right
- Pattern defined left most is attempted first and gradually moves right to attempt
- All viable Patterns are evaluated before proceeding with next character in the text.
Example
Left to Right Problem: Find all words that contain car or carpet
Pattern: car | carpet Text: carpet and car
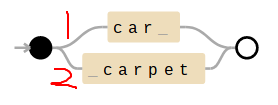
Regular Expression Engine will try to match car firstly
one character per time to see it's fully match or not, if can't match,
it will backtrack to 'c', and try to match the second choice,
'carpet'
这种写法的结果就是:只匹配到了 car 而匹配不到
carpet
Pattern Adjust
下面我们来修正一下,使其可以正确匹配:
Pattern:
\b(car|carpet)\b匹配过程:
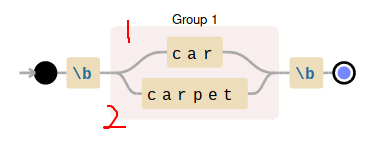
当正则引擎在文本中遇到
carpet时, 先匹配car,逐个字符匹配,c a r然后该匹配边界了,发现为p不是边界,然后正则引擎沿原路径回溯,准备匹配carpet路径,逐个字符匹配发现可以,就匹配成功。但是,我们可以看出根据 Regexp Engine 遵循的 Left to Right 方式,这种 Pattern 在遇到
carpet的时候,仍然需要回溯,这样大大降低了效率。为加深对正则引擎了解,我们再看一下
Pattern:
\bcar|carpet\b这个 Pattern 和修正的只有一对括号的区别,却是正与错的差距。 因为|会将整个模式分成两半,所以这个 Pattern 基本等同于:(\bcar)|(carpet\b)的作用。
Pattern Adjust Again
Pattern; \bcar(pet)?\b
Summary
Pattern and Text are evaluated Left to Right
In-order to minimize backtracking, extract common patterns out
car(pet)? Write more precise patterns first followed by
more generic patterns
Greedy,lazy and Backtracking
Greedy -Consume as much of the input text as possible and then give-up the characters to match rest of the pattern.
- 量词
*, +, ?是贪婪的(greedy), 它们会尝试匹配尽可能多的输入文本。(其中?贪婪和懒惰区别不大) - 有时候,当这些量词应用在像
.这样的通配符上时,会消耗掉你全部的文本,从而导致饿死 Pattern 中的后续部分。 - 通过在
*, +, ?等后面再加一个问号,即:*?, +?, ??,使其变为懒惰模式。 - Regexp Engine 评估计算, 每次回溯一步,来看它是否能满足 Pattern 中的后续部分。
Example
Problem:Find sentences ending with a number and extract the number.
Pattern: .+(\d+)[.!] text: First 1234. Second 5678!
Regexp Engine 匹配步骤: 首先, . 是贪婪的, 会匹配
First 1234. Second 5678! , 然后发现后面的部分:
(\d+)[.!] 被饿死了。继而向前回溯一个字符,
First 1234. Second 5678 , 然后 (\d+)
还是被饿死了, 再向前回溯一个字符 First 1234. Second 567 ,
于是匹配成功。 .+ 匹配:
First 1234. Second 567 , (\d+) 匹配了 8,
[.!] 匹配了 !
Lazy
Lazy — Consumes as few input text as possible and then attempts to match rest of the patterns
量词 *, +, ? 是贪婪的
- Quantifiers
*,+,?can be turned to Lazy by adding a?After the quantifier
Example: *?, +?, ??
- Idea behind lazy is' to match as few times as possible for quantifiers and proceed to match rest of the pattern
- When there is no match for a pattern, lazy mode backtracks on the pattern and expands to match more characters in input.
Example
Pattern: .+?(\d+)[.!] text: First 1234. Second
5678!
通过 ? 使得 + 变成 lazy 模式。lazy 使得
. 先匹配尽可能少的, 于是匹配了 F, 然后进行
匹配,发现没有数字可以匹配了, 那就 Pattern 向前回溯一步, 接着通过
. 匹配, 于是匹配 Fi , 然后再次进行
匹配,发现仍然不行,进而 Pattern 再次回溯, Pattern 如此反复回溯, 最终
. 匹配了 First , \d 匹配了
1234 , 标点符号匹配了 .
Groups
Indexed, Named, Non Capturing
用处一:
Break a pattern into sub-patterns; pinpoint location of matching
string and sub-strings Groups are any pattern specified inside a
parenthesis () Reuse common patterns, Mark as optional —
minimize backtracking car(pet)?
Extract Values:
(?P<year>\d{4})(?P<month>\d{2})(?P<day>\d{2})
用处二: Capture Repeating Sub-Patterns
\d+(, \d{3})*(\.\d{2})?
Matches: 123.67 123, 456.75 127, 546, 245.58
Indexed Group
Capture matching substring
• Problem: Extract year, month and day from string yyyymmdd • Pattern: ()()() • Text: 20160501
Access by group number
Groups are numbered from left-to-right. Every open parenthesis is assigned anincreasing number starting from 1 Group 0 => Refers to whole pattern Group 1 => () Group 2 => () Group 3 => () python 中 group() 方法默认返回 whole pattern
Named Group
在左括号后加
?P<group_name>,例如:(?P<name>\d+?)
Non-Capturing Groups
有时候我们使用 group 只是为了匹配,而并不想捕获 group 的值。例如:
Groups are used here to capture repeating patterns, 比如上面 pattern 的
(,\d{3})*(\.\d{2})?
两个分组,我们并不关注分组自己的内容,我们使用分组是为了更好地匹配整体。Group
capture is expensive, turn it off when not needed
Match without group capture
Problem: Match number of format 999,999,999.99 Capturing Groups Version Pattern:
\d+(,\d{3})*(\.\d{2})?Text: 20,198,425.12
方法:在分组 ( ) 内的开头增加 ?:
Non-Capturing Group (?:) Pattern:
\d+(?:,\d{3})*(?:\.\d{2})?
Group - Back reference and Substitution
- Back reference refers to a group that was captured earlier and used subsequently in
• Problem: Identify repeating words • Pattern:
(?P<word>\w+)\s+(?P=word)\b • Text: capture duplicate
duplicate words
• Problem: Identify repeating letters • Pattern:
(?P<1etter>\w)(?P=1etter)
- Substitution pattern used for text replacement can refer to previously captured group
\g• Problem: Identify repeating words and remove repetition • Find Pattern:
(?P<word>\w+)\s+(?P=word)\b• Replacement Pattern:\g<word>使用
\num比如:
\1表示第一个分组
Lookarounds
Lookbehinds and lookaheads (also called lookarounds) are specific types of non-capturing groups (used to match a pattern but without including it in the matching list)
Look ahead — Peek at what is coming up next without consuming the characters Look behind — Look at what came before current character Both are called zero width assertions - Returns True or False - Does not consume any characters
- Look ahead is similar to "if (expression) yes_expression"
- Look ahead and Look behind can contain patterns Allows you to implement more complex conditional logic
- Does not backtrack — Once it return a true/false, job is done. If pattern does not match, Look ahead/Look behind would not backtrack to try another match.
these two assertion don't consume and match the Look part.
| Symbol | Description |
|---|---|
?= |
Positive Lookahead(希望未去的前方(右边)有) |
?! |
Negative Lookahead(希望未去的前方(右边)无) |
?<= |
Positive Lookbehind(希望已来的后方(左边)边有) |
?<! |
Negative Lookbehind (希望已来的后方(左边)边无) |
Regular Expression Proformance
Backtracking Exponential Delay Example
Type of patterns that can cause performance issues
Problem: Match a word Pattern: ^(\w*)*$ Text (Positive):
12345678901234567890 Text (partial match): 12345678901234567890!
Pattern works perfectly for positive matches. With partial matches, perfomance degrades rapiadly and every addtional character double the response time.
正则引擎: Match 1: 1 Match 2: 12 Match 3: 123 Match 4: 1234 Match 5:
12345 - ! Does not match stops now. And end of string $
match fails. 于是, Pattern 进行回溯,匹配出两组:(1234)(5),
然后最后还是有 ! 不能满足结尾。
因此,继续回溯,匹配出两组:(123)(45), 然后最后还是有 !
不能满足结尾。 就这样回溯到头,然后匹配失败
4.2. Issues and Fix
Pattern: (\w*)* => (\w*)(\w*)(\w*)
多个相似的贪婪模式捕获相同的字符(串),会导致严重的性能问题。
修改方式:
- Option 1: No need to have a group level quantifier
^(\w*)*$ => ^(\w*)$
- Option 2: Precise terminating condition. Every word in group should end in a word boundary.
^(\w*)*$ => ^(\w*\b)*$
- Disable group capture
^(\w*)$ => \w*$ or
^(?:\w*)$
Module Versus Compiled Regex Method Invocation
Compiled Regex Objects vs Module Methods You have two ways to invoke regular expression functionality
- Create a compiled object and invoke methods of that object
- Use re module methods directly
编译对象的方法提供了一些微调参数。 例如:搜索的开始、结束位置
re module caches the compiled version of patterns and reuses them
- Python 3 Pattern Cache Size is 512
- Python 2 Pattern Cache size is 100
- When patterns exceed cache size, current implementation of re simply clears the entire cache.
Best Practice: For high performance and/or high frequency invocation of patterns — Use compiled objects, hold reference to the objects and reuse them.
总体来说: 遇到一个 pattern 需要重复匹配多次,或者多个 pattern 匹配的情况,使用编译好的 pattern 对象更加快。 re module 在重复次数少, python3 下 pattern 缓存个数比较少于缓存值:512 时,效果还行。
Match Unicode Characters
vscode 和 pyhton3 的 re 模块默认的都是 unicode 字符集,因此在 Python3
的 re 模块或 vscode 中都直接使用即可: [\u4e00-\u9fa5]
匹配的是能组成单词的字符,在 python3 中 re 默认支持的是 unicode 字符集,当然也支持汉字。只要加入 re.A 就可以解决这样问题,