机器学习基本概念
机器学习(Machine Learning)定义
机器学习的本质就是寻找一个函数 function,来寻找一个输入 input 与输出 output 之间的映射关系。
机器学习的应用
| 场景 | 函数/预测 | |
|---|---|---|
| Speech Recognition | f(一段语音)=文字 | 输入声音,输出语音内容 |
| Image Recognition | f(图片)=对象 | 输入图像,输出图像对象的描述 |
| Playing Go | f(棋盘) = 下棋子的位置 | 下棋子的位置, 输出下一步棋 next move |
| Self-driving Car | f(各种传感器参数) = 方向盘角度 | 根据对道路以及路障的识别,得出方向 |
| Recommendation | f(使用者 A, 商品 B)=购买可能性 | 根据用户与商品的关系,得出购买可能性 |
基本概念
回归 regression:The function outputs a scalar(标量数值)
分类 classification:Give option(classes),the function outputs the correct one.
结构化学习 structures Learning:create something with structure(image,document). 函数输出是以某种结构形式。
打个比喻,如果用一张数学试卷来描述,分类是给定选项的,像判断题就是二分类问题,研究对象是不是这个类的问题,而选择题就是多分类问题,有多个类别选择一个类别;回归更像是简答题,你的自己算出标量值;而结构化学习可以是一整张试卷,也可以是试卷的所有选择题或所有简答题。那如果是多选题呢?多个选项多个正确答案,例如一张栀子花图片(图从百度上借来),它既属于花类,也属于栀子花类。其实也没事,设置多标签 multi-label。
How to find Function?
Case Study
Function with unknown Parameters
模型学习的三步骤:建立模型、定义损失函数、优化参数
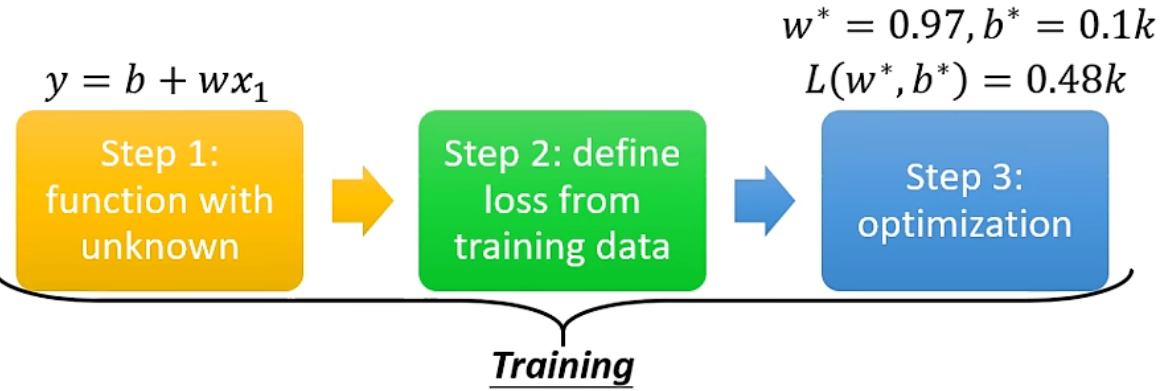
- 根据 domain knowledge1,猜测一个能完成任务的未知函数
- 根据训练数据,定义 loss 函数,用来衡量函数解和真实情况的差距。
- 通过不断优化,找到能使 loss 值最小的参数,也就是使函数解尽可能接近真实情况。
这三步都属于 training 过程。最后 train 出来的参数能使模型预测最准,将这个模型用于预测没有看过的资料的过程叫做 testing,一般 testing 的 loss 会比 training 的 loss 高。
Regression(回归)
下面以预测 YouTube 频道次日流量为例,讲一个回归任务的流程。基于后台资讯(domain knowledge),我们猜测一个带有未知数的模型。y 是预测的观看量;x1 是今天的观看量,称为 feature(自变量);w 和 b 就是模型参数,需要学习之后确定下来。
第一步:建立一个含有未知参数的函数,从而规定一类函数集合,这个函数就是机器学习里的模型 model。
 根据 domain knowledge2,猜测一个能完成任务的未知函数。在这里我们猜测:\(y=b+w*x_1\)。\(x\) 是已知的特征 feature,\(w\) 为权重 weight,\(b\) 是偏置 bias, \(w\)和\(b\)都是未知的参数,需要从数据中学习。
根据 domain knowledge2,猜测一个能完成任务的未知函数。在这里我们猜测:\(y=b+w*x_1\)。\(x\) 是已知的特征 feature,\(w\) 为权重 weight,\(b\) 是偏置 bias, \(w\)和\(b\)都是未知的参数,需要从数据中学习。Define loss from Training data
要评价 function/model 的好坏,就需要定义评估 model 的函数,即定义损失(loss)函数,计算 model 在所有样本点上的损失总和。Loss 是关于未知参数的函数,每一对未知参数的具体值 \((w_1, b_1)\),对应一个预测模型,Loss 函数即是评估该预测模型和真实模型(训练数据)的拟合程度(损失/差值)。从而通过变换 \(w\) 和 \(b\) 最小化 Loss 值,就是不断调整预测模型来拟合训练数据。评价一个预测模型的好坏,即:对每一个训练样本,计算其模型输出与真实值(label)之间的误差(e),也就是损失,整个模型的损失函数就是全部训练样本误差的平均值。
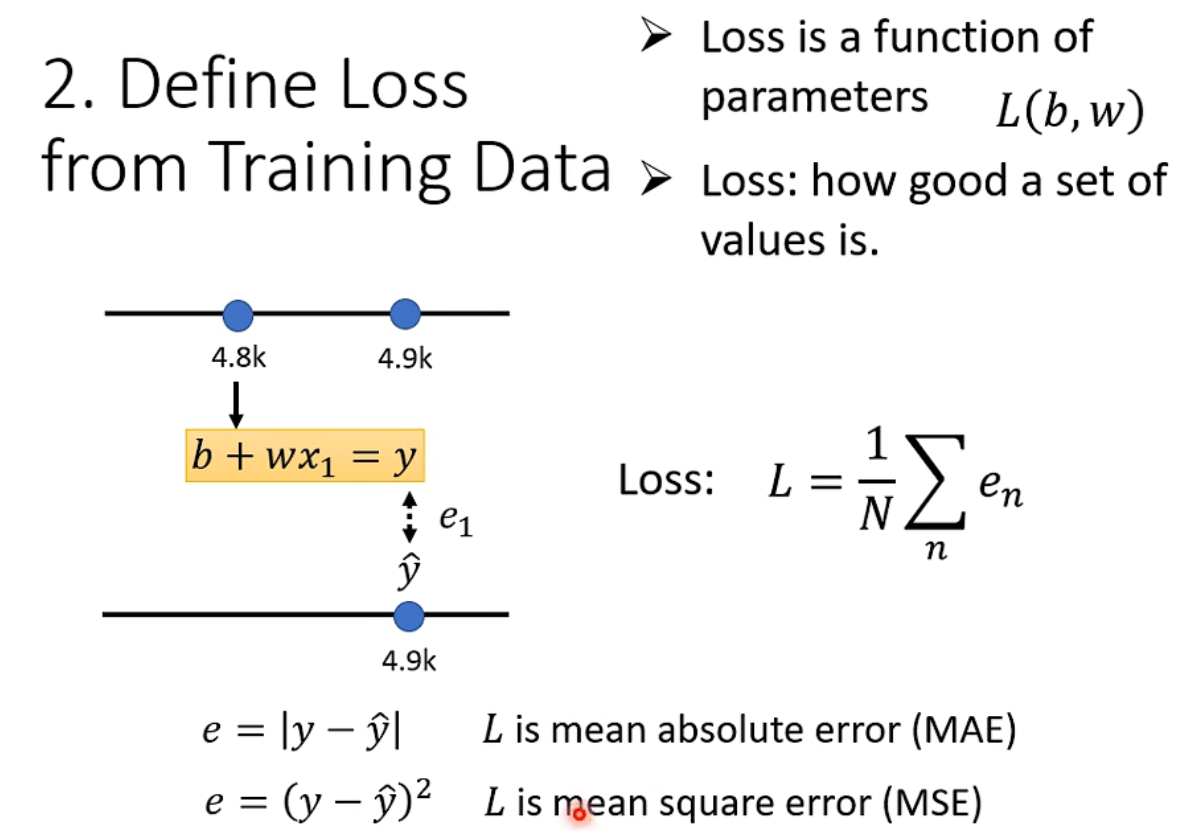
loss 常用的评估方式有:
MAE(mean absolute error) 平均绝对误差
MSE(mean square error) 均方误差
cross-Entropy 交叉熵
If y and are both probability distributions,则选择 Cross-entropy
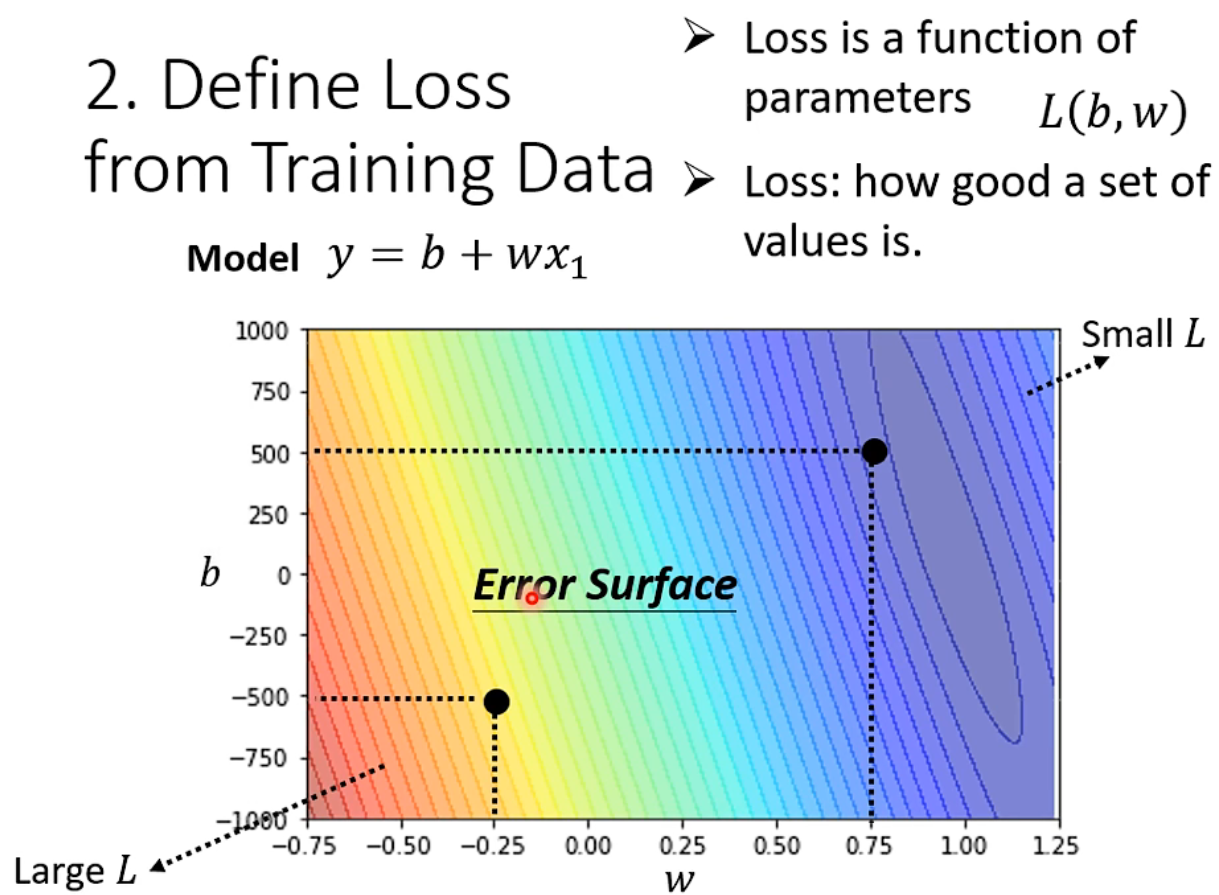
Error Surface 误差曲面:绘制出参数作为横、纵坐标和 L 之间的映射关系,就形成了二维的误差面,颜色代表 loss 的大小。
Optimization
优化的目标是找到使 Loss 最小的参数,即求解\(w^{*}, b^{*}=\underset{w, b}{\arg \min } L\)
优化方法:梯度下降 gradient descend
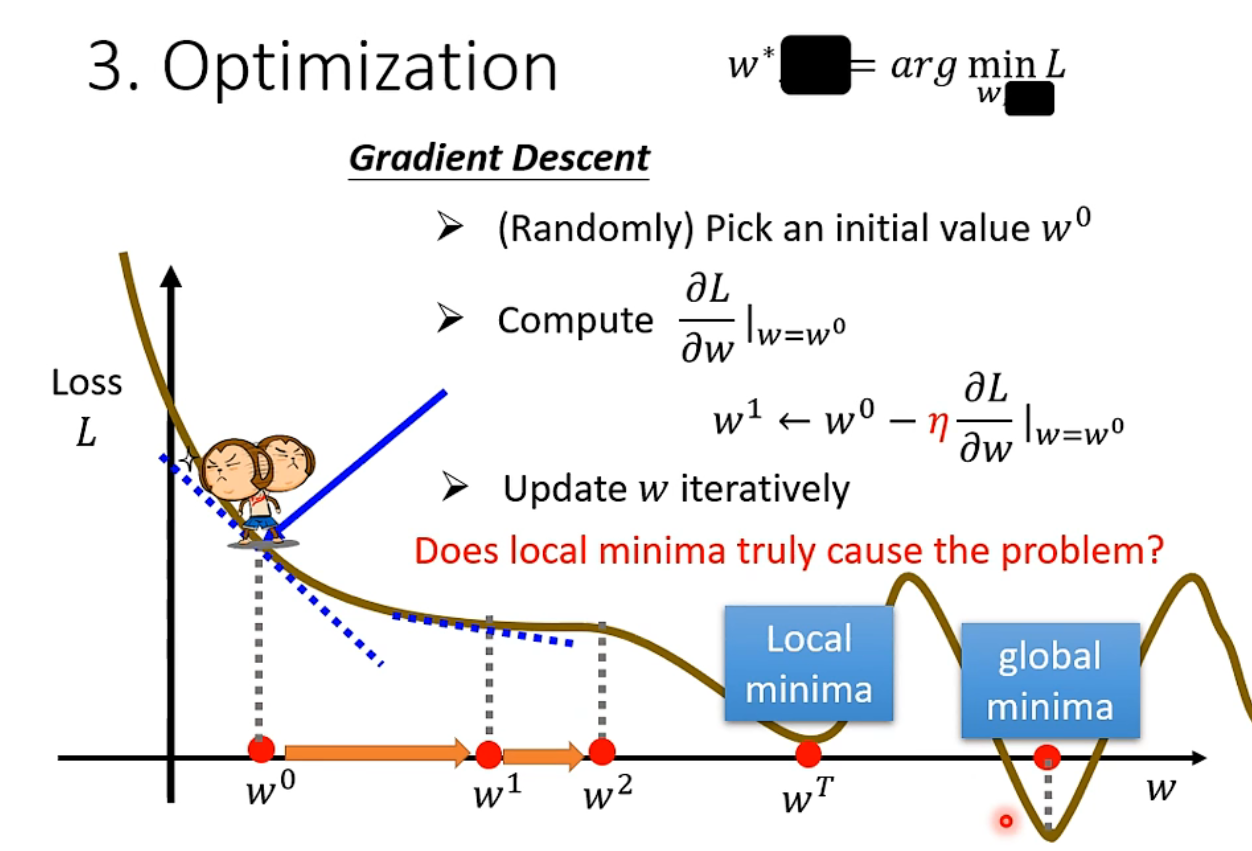
一、以一个参数 \(w\) 举例,画出其对应的 error surface
下面例子中先不看参数 b,只观察参数 w。梯度下降的做法是先随机初始化一个 w0,然后计算 w0 处的微分,可理解为斜率。当微分为负数时,在 w0 处,loss 关于 w 递减,所以增大 w 使 loss 下降。当微分为正数时,在 w0 处,loss 关于 w 递增,所以减小 w 使 loss 下降。
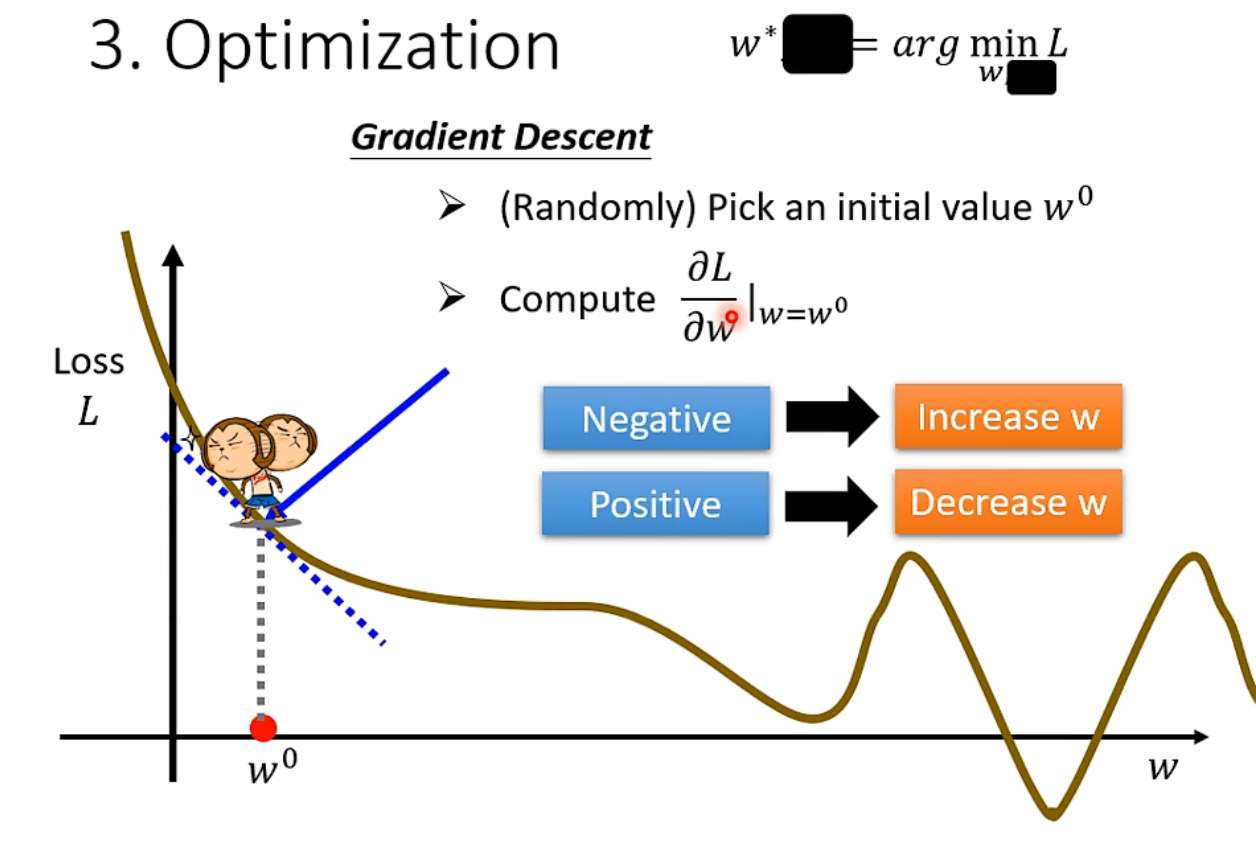
先随便选个 $w$,然后计算它的梯度(也就是斜率),当梯度为负时就应增大 $w$。增大 x 的幅度(步长)由学习率 learning rate 和斜率决定。学习率是一个需要提前设定的超参数 hyperparameter(相比超参而言,$w$和 $b$ 这种参数是要通过数据学习的)
如此迭代多次更新 $w$(停止条件:迭代次数达到阈值(超参)或微分趋于 0),梯度下降的问题在于只能找到局部最小值(但其实这是个假问题,将在后面课程中解释)
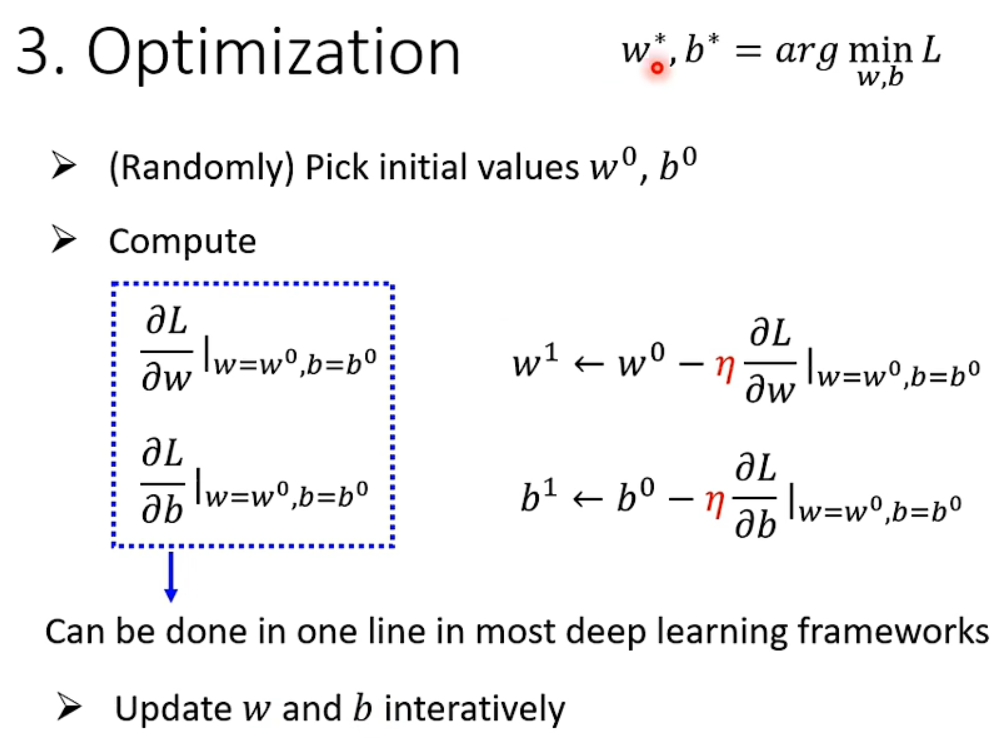
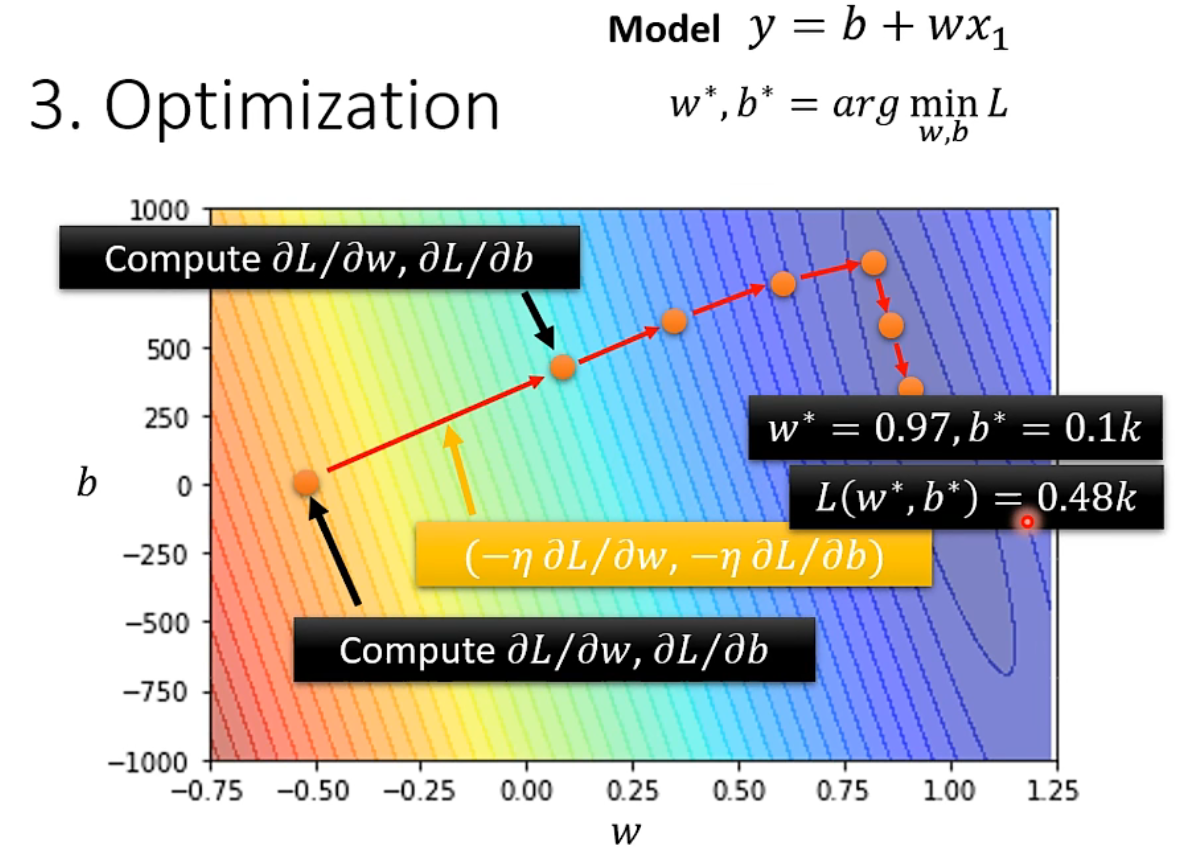
二、推广到两个参数的例子:随机选取初始参数,计算其偏微分,使用梯度下降的方式同时更新两个参数,多次迭代直至停止。
测试
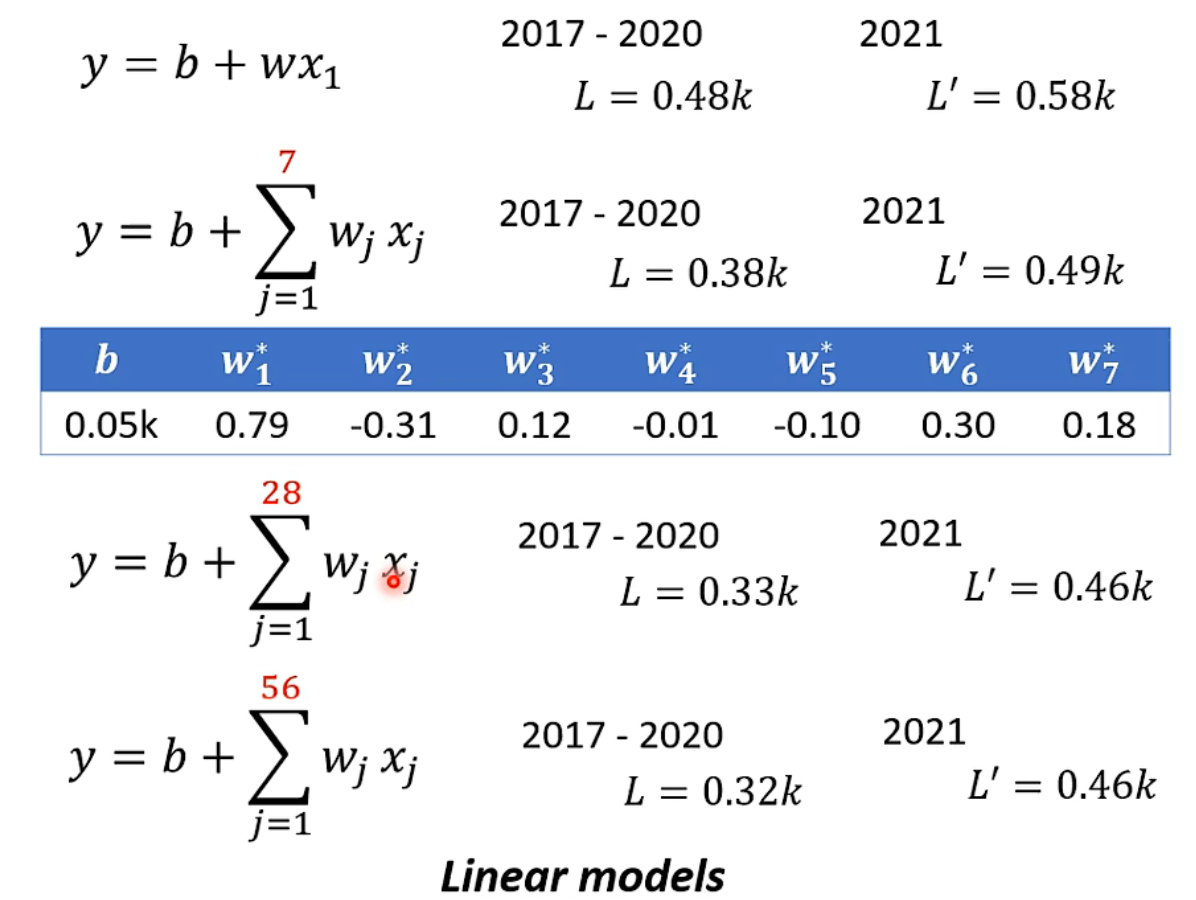
通过训练阶段得到 \(w^{*}=0.97, b^{*}=0.1 k\) ,训练集上的损失函数 \(L\left(w^{*}, b^{*}\right)=0.48 k\) ,测试集上的损失函数 \(L^{\prime}=0.58 k\) a
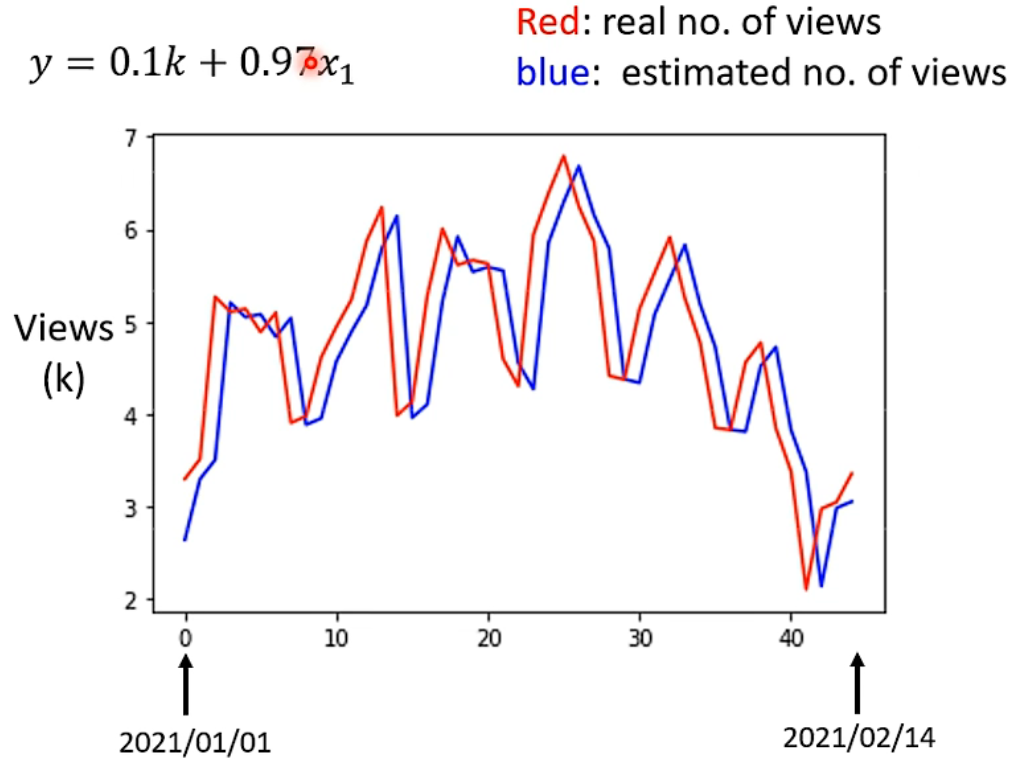 通过上图真实值和拟合值对比,可以看出数据有明显的周期性,因此修改自变量为前
j 日的流量。拟合 1 日、7 日、28 日、56
日的数据来预测下一日流量。可以发现随着自变量日期增加,在测试集上的结果不再变好。
通过上图真实值和拟合值对比,可以看出数据有明显的周期性,因此修改自变量为前
j 日的流量。拟合 1 日、7 日、28 日、56
日的数据来预测下一日流量。可以发现随着自变量日期增加,在测试集上的结果不再变好。
常用优化方法有 Adam、梯度下降(Gradient Descent)等。