模型选择-过拟合与正则化
intro
如果第一轮模型拟合效果不好,凭借 domain knowledge 对结果的分析,可能对初始模型猜测不恰当或者对其他影响因素缺乏考虑,需要重新设计模型。
回归问题的损失函数是凸函数(convex),意味着一定会找到全局最优解。但是,其它的机器学习问题中,多个参数的梯度下降可能会陷入局部最优解。
选择模型时,更倾向于选择“平滑”的模型。因为当数据有噪声干扰时,越平滑的函数受到噪声的干扰越小。
过拟合
越复杂的模型拥有更大的函数集合空间,理论上经过训练都可以得到好的预测能力,但是取决于梯度下降的是否能找到了 local minima. 事实上, A more complex model does not always lead to better performance on testing data.This is Overfitting.

可以看到在测试集中,随着模型复杂化,前面误差在减小,但是后面模型越复杂,测试集误差越大。越复杂的模型不一定在测试集中有更好的结果。这种现象就是过拟合。

过拟合的一个解决方法是使用正则化,通过正则化来降低模型的泛化误差。
正则化

最初的 Loss 函数采用 square error,只考虑了 Prediction 的 error regularization 主要是加上一项额外的 term,这项额外的 term: \[\lambda \sum_{\circ}\left(w_{i}\right)^{2}\](\(lambda\) 为超参数)
正则项的意义:\(w_i\) 越小,该项越小,Loss 越小。 参数 \(w_i\) 偏小,函数更平滑,函数值随 x 变化的变化幅度小, 即:\(w_i\Delta{x}\) 越小。因此,在噪声影响输入时,平滑函数受到噪声的影响更小。
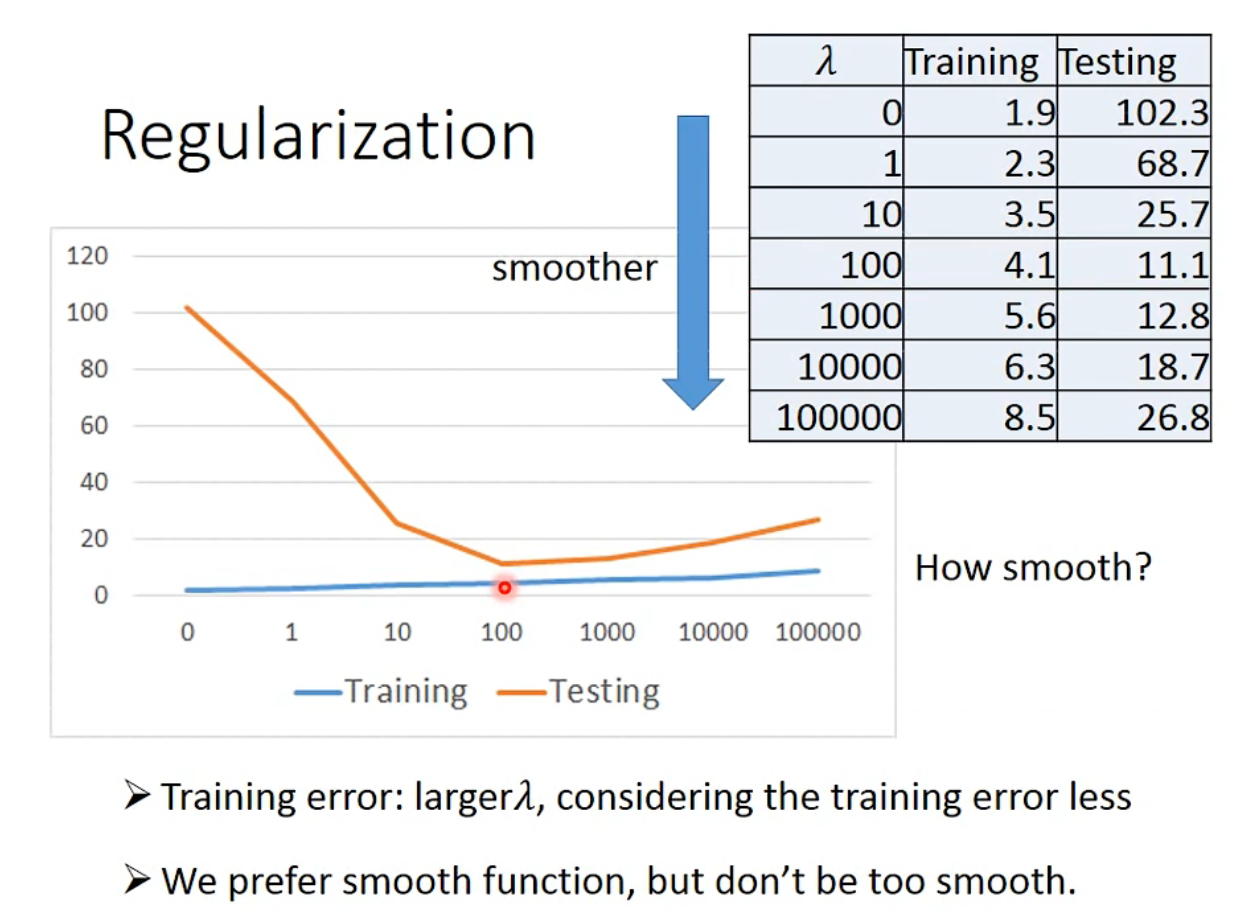
通过调整 \(\lambda\) 超参数,得结果如下: \(\lambda\) 越大,function is more smoother,但是在训练集上的误差越大,因为 \(\lambda\) 我们对正则项的考虑越多,对拟合的误差项考虑越少。但是 \(\lambda\) 越大,在测试集上的误差从小到大,说明一定范围内更平滑的函数可以抵抗噪声,但是太过平滑的 function,拟合效果过差。因此我们需要选择调整 \(\lambda\) 获得使 loss 最小的模型。
注意:正则化不需要考虑 bias(b),因为 bias 对函数的平滑程度没有贡献,它仅仅是上下移动 function 而已。