torch dataset 相关函数
以 MNIST 举例,
train_dataset.data获得 feature/image 的 tensor, 其 shape 为torch.Size([60000, 28, 28])train_dataset.targets获得 label 的 tensor,其 shape 为torch.Size([60000])train_dataset[0]获得二元组(image, label)表示第一条记录train_dataset[0][0],train_dataset[0][1]分别为第一条数据的 image 和 label 对应的 tensor
数据集独立同分布
MINST 数据独立同分布和非独立同分布的代码:
MNIST dataset distributed as IID & Non-IID | Kaggle
MNIST 数据集中各类别数目与比例: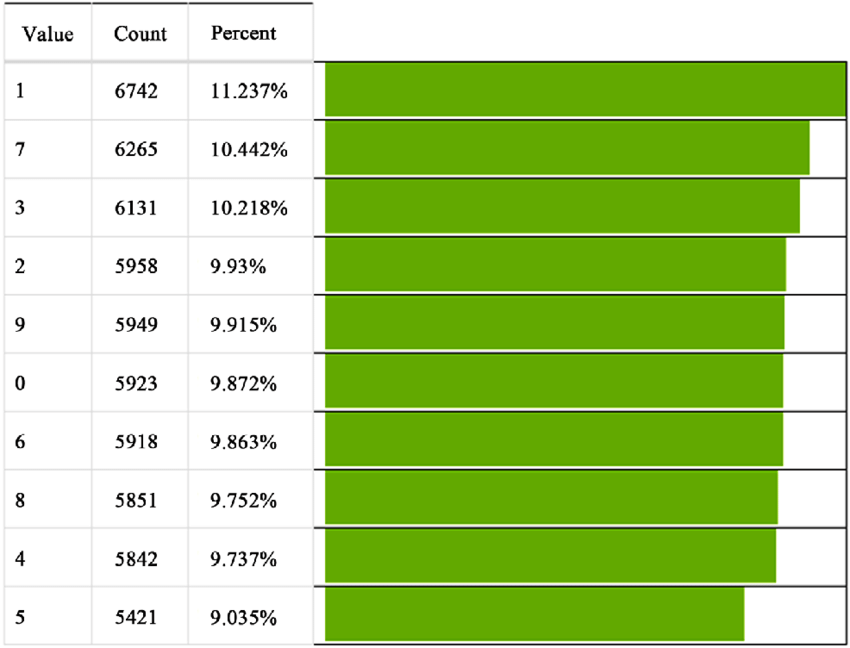 from paper: A Minimal
Subset of Features Using Feature Selection for Handwritten Digit
Recognition
from paper: A Minimal
Subset of Features Using Feature Selection for Handwritten Digit
Recognition
Normalize dataset
归一化的目的就是使得预处理的数据被限定在一定的范围内(比如 [0,1] 或者 [-1,1]),从而消除奇异样本数据导致的不良影响。
奇异样本数据是指相对于其他输入样本特别大或特别小的样本矢量(即特征向量)
例如:age 特征一般范围 [0, 100], 工资特征一般范围:[2000, 6000], 那么采用梯度下降法训练过程中,寻找最优解的梯度下降过程中,路径就有可能被工资特征的影响所主导,从而导致收敛过程缓慢,甚至收敛效果不好。
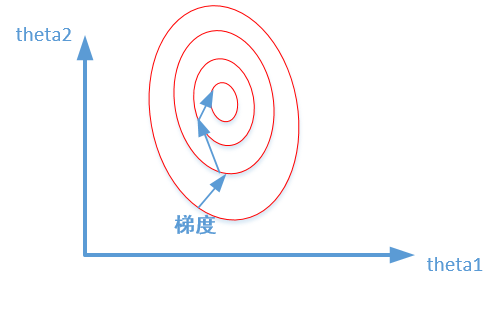
例如下图损失函数的等高线,未归一化的特征会导致损失函数的等高线变成椭圆形状,从而导致梯度下降法收敛过程缓慢,甚至收敛效果不好。
归一化之后,损失函数的等高线变成圆形,从而导致梯度下降法收敛过程更加平缓,收敛速度加快。
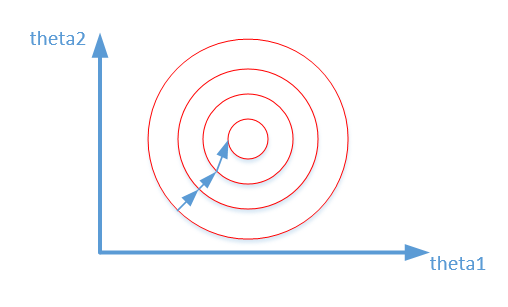
数据归一化效果:收敛过程更加平缓,收敛速度加快
常见数据集 mean std:
MNIST: mean, std = (0.1307,), (0.3081,) FashionMNIST: mean, std = (0.2861,), (0.3528,) CIFAR10: mean, std = (0.4914, 0.4822, 0.4465), (0.2470, 0.243, 0.261)
例子:
1 | trans = transforms.Compose([ |
torch.ToTensor()将图片转换为 FloatTensorConverts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0], 将所有数除以 255,将数据归一化到 [0,1]
torch.flattentransforms.Lambda(torch.flatten)将数据集 flatten 成一维transforms.Normalize对应 channel 的数据,均值和标准差,运算如下:
x = (x - mean) / std经过 transforms.Normalize 数据不一定服从正态分布,结果也不一定都处于 [-1,1] 之间Normalize: 减去均值,除以标准差只是将数据进行标准化处理,并不会改变原始数据的分布。每一个 channels 上所有 batch 的数据服从均值为 0,标准差为 1。
Torch 分割数据集 sampler vs subset vs random_split
如果一直不停使用一个数据集,且需要根据特征使用数据集的不同部分,则使用 sampler
为了避免重复性创建数据集,只针对一个数据集做后续的处理的话,可以采用 sampler,而不必采用 subset. You can define a custom sampler for the dataset loader avoiding recreating the dataset (just creating a new loader for each different sampling).
定制化获取数据集的子集,后续只用该子集 / 只使用大数据集的一部分子集训练
直接根据原始数据集创建一个 subset 子集即可。
python - Taking subsets of a pytorch dataset - Stack Overflow
参考:Pytorch 继承 Subset 类完成自定义数据拆分 - 编程宝库
动态变化权重的采样器, [feature request] [PyTorch] Dynamic Samplers. · Issue #7359 · pytorch/pytorch
联邦学习中服务端对数据集进行分割,然后分发给 client 从而模拟 local model training with the share of data。
可以采用 `random_split
random_split(dataset, lengths) works directly on the dataset.
Two input arguments:
- The first argument is the dataset.
- The second is a tuple of lengths.
returns two Datasets with non-overlapping indices, which were drawn randomly based on the passed lengths, while SubsetRandomSampler accepts the indices directly.
If we want to split our dataset into 2 parts, we will provide a tuple with 2 numbers. These numbers are the sizes of the corresponding datasets after the split.
1
train_dataset, val_dataset = random_split(dataset, (6000, 899))
It's important to note that in federated learning, both
random_splitandsamplercan be used together, but their roles are slightly different.random_splitis typically used on the server side to divide the global dataset into subsets for clientswhile
sampleris used on the client side to control the data sampling strategy during local training
数据集本地分份,然后使用
train_dataset 读取了数据集的 dataset 对象。
[不推荐] 将 tensor split 成 K 个 tensor,
torch.tensor_split(train_dataset.data, K_partitions, dim=0)[推荐] 通过 reshape 或者 view 来改变 tensor 的视图
train_dataset.data.reshape((K_partitions, len(train_dataset)//K_partitions, -1))
Change label in dataset
推荐如下方式,将标签等于 4 的标签设为 0,将标签等于 9 的标签设为 1
train_dataset.targets[dataset.targets == 4] = 0
train_dataset.targets[dataset.targets == 9] = 1
注意对训练集和测试集都要改变 Change labels in Data Loader - vision - PyTorch Forums